苹果汁 = 榨汁机(苹果)7 函数
Note
本章内容较多,可以按两个层次学习。
必修主线:函数定义、参数、返回值和作用域基础
- 函数的基本概念:参数、返回值
- 定义函数:
def、函数名、参数、缩进、return - 函数命名规范
- 基础示例:加法、求最大值、圆面积
- 不返回值的函数,以及返回
None print()和return的区别pass- 位置参数和关键字参数
- 默认参数
- 可变默认参数陷阱
*args:接收不定数量的位置参数**kwargs:接收不定数量的关键字参数- 拆包:
*和** - 多返回值与解包
- 可变类型和不可变类型作为参数
- 在列表推导式中使用函数
- 变量作用域基础:局部变量、全局变量
global
进阶学习:函数参数细节、递归和函数式编程
- Docstring 与类型标注
- 位置专用参数
/和关键字专用参数* - 浅拷贝和嵌套可变对象
nonlocal- 递归
mapfilter- 混合使用
map和filter lambdakey=函数与排序/选最值map/filter的惰性- 函数是一等公民
- 函数作为参数
- 返回函数的函数
reduce- 闭包
- 函数 vs 向量化
在本章中,你将学习到:
- 什么是函数? 理解函数的概念,以及它如何减少重复代码,并让代码结构更清楚。
- 如何定义和调用函数? 掌握
def关键字、函数名、参数、函数体和return语句的基本语法。 - 参数的不同用法: 学习位置参数、关键字参数、默认参数,以及如何处理不定数量的参数 (
*args和**kwargs)。 - 函数中的变量作用域: 理解局部变量、全局变量以及LEGB规则。
- 不同数据类型作为参数时的影响: 了解当可变与不可变类型作为参数传递给函数时会发生什么。
- (进阶) 递归的初步认识: 函数如何调用自身来解决特定问题。
- (进阶) 函数式编程初步: 了解
map、filter、lambda表达式,以及高阶函数和闭包的概念。
通过学习本章,你将能够把复杂任务分解为一个个小函数,让代码更有结构,也为后续更复杂的数据分析任务打下基础。
首先,Python中的函数基本上可以类比我们熟悉的数学函数,比如正弦函数:
\[ sin(\pi) = 0 \]
但更广泛地理解,可以认为:把任何东西(“参数”)扔给函数,函数返回某个结果(“返回值”)给你:
例如:我们把 \(\pi\) 扔给正弦函数 \(sin\) ,会得到 \(0\) 。
例如:把榨汁机看成一个函数,那我们把苹果扔进榨汁机,就能得到苹果汁。
其中
- 榨汁机:函数
- 苹果:参数(你要丢给函数的东西)
- 苹果汁:返回值(函数丢给你的东西)
- (进阶概念)副作用:除了返回值,函数还影响了一些其他东西。(后面会提到)
写成代码,大概是:
现实的例子,我们面前已经用过的,比如求List的长度:
a = [1,2,3,4,5]
a_size = len(a)
print(a_size)看a_size = len(a)这个代码
len():函数名len(a):其中a是参数,即“你提供给这个函数的东西”a_size = len(a):会返回a的长度(元素的数量),你把这个结果放在变量a_size之中
一般而言,写函数我们往往希望达到:
- 代码复用 (Reusability):避免重复编写相同的代码块。
- 模块化 (Modularity):将复杂问题分解为更小、更易于管理的部分。
- 可读性 (Readability):结构清晰,易于理解代码的逻辑和意图。
- 可维护性 (Maintainability):修改或调试时,只需关注特定函数。
比如在数据分析中,你可能需要多次对不同的数据集进行同样的清洗操作(如去除缺失值、转换数据类型),这时把清洗步骤封装成一个函数,就可以反复使用。
7.1 定义一个函数
在Python中
- 定义一个函数的关键字是
def, def后,是函数名,小括号内是参数(这个函数要接收的东西),最后是冒号- 函数体,要有“1个缩进”
- 返回关键词是
return。如果函数执行完都没有遇到return,则返回None
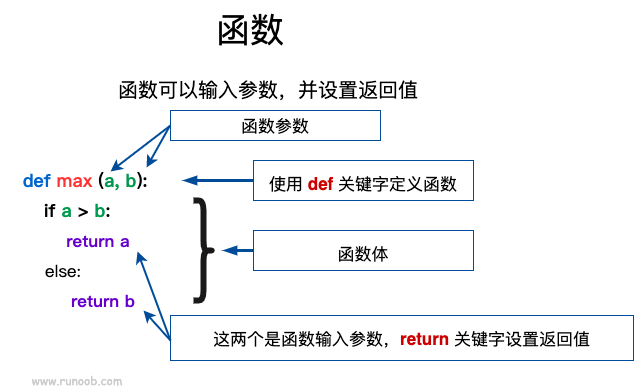
函数命名的约定:
- 推荐使用
snake_case(小写字母和下划线) 命名风格 - 避免和内置的名称重名(如前面截图中定义的
max()函数)。回忆我们前面说的,变量名(和函数名)只是一个标签,避免你定义的函数顶替掉内置的函数。
7.1.1 例:加法函数
举一个最简单的例子,我们要写一个加法函数,其作用就是把2个变量相加。或者说,你给这个函数“传递2个参数”,这个函数会返回它们的和。
#%% 定义一个加法函数
def add(x, y):
z = x + y
return z逐行解释一下
第一行: def add(x, y):
- 定义一个函数,由
def开头 - 接着是你给这个函数起的名字
add - 名字后面是小括号,里面包含了这个函数的“参数”。这里是2个参数,命名为
x和y。调用这个函数时,需要给它提供这2个参数。 - 和
if、for语言等一样,最后是冒号,不要忘记。
注意:关于参数,2个参数的名字你可以自己定义,不一定是x和y。这2个参数的名字,如同一切变量名一样,最终会”指向”2个值,所以你在函数的内部,就可以用这2个名字,来引用这2个值
第二行:z = x + y
- 注意,前面有“1个”缩进(Tab),指示这个语句比函数本身低一级
z = x + y。函数体内的2个参数已经有对应的值,所以可以直接使用x和y。
第三行:return z
- 前面还是“1个”缩进,这是和
z = x + y同一个层级的代码。 - 返回使用
return语句。这里把和z,返回给上一层。
定义好之后,我们可以像使用任何函数一样调用它
我们来一个很熟悉的代码。
a = 1
b = 2
c = add(a, b)
print(c)7.1.2 Docstring 与类型标注(推荐)
良好的文档字符串与类型标注有助于阅读、IDE 辅助与静态检查。
def add(x: int, y: int) -> int:
"""返回两个整数的和。
参数
x, y: 两个整数
返回
int: x + y
"""
return x + y
print(add(1, 2))
help(add)7.1.3 例:求两个数的最大值
思路:
- 如果a > b,则返回a。
- 否则返回b。(此时a <= b,两者相等时返回b也可以)
#%% 定义一个函数,接收两个参数,返回其最大值
def my_max(a, b):
if a > b:
return a # 返回a
else:
return b # 返回b
print(my_max(3,5))7.1.4 例:计算圆的面积
另一个例子,已知:圆的半径是\(r\),我们要计算圆的面积,公式就是\(y = \pi r^2\)。
我们准备写一个函数来做这件事:
- 这个函数会根据我们提供的半径\(r\),返回一个圆的面积给我们。
- 这个函数需要接受
r作为参数 - 函数体内计算面积,并把结果返回
def calc_area(r):
return 3.14159 * (r ** 2)x = 5
area = calc_area(x)
print(f"半径为{x}的圆,其面积为{area:0.2f}")7.1.5 不返回值
若函数不需要返回任何值,不写return语句,或者return语句后不返回任何值
#%% 这2种都是可以的
def hello():
print("hello") # 不写return
def hello2():
print("hello")
return # 写return但不包括返回值
hello()
hello2()7.1.6 print() 和 return 的区别
print() 是把内容显示在屏幕上,方便人查看;return 是把结果交还给调用函数的代码,方便后续继续计算。
def add_print(x, y):
print(x + y)
def add_return(x, y):
return x + y
result1 = add_print(1, 2)
result2 = add_return(1, 2)
print(result1) # None,因为 add_print 没有返回值
print(result2 + 10) # 可以继续计算7.1.7 什么也不做的函数
有时候需要先占用函数名,但是函数的内容想以后再写,此时可以写一个空函数。函数体内只需要使用pass语句。
特别地,没有return语句(例如现在这种情况),或者return语句不返回值的时候,函数会返回一个None。
def do_nothing():
pass
print(do_nothing())7.1.8 小练习
结合前面的学习内容:
- 实现一个函数
my_count(),计算并返回一个列表的元素数量,但不要使用自带的len()函数。
print(my_count([2,3,4,5])) # 应该输出 4- 实现一个函数
my_max_len(),找到一个字符串列表中最长的字符串,但不要使用自带的max()函数。
print(my_max_len(['a','bbb','cc'])) # 应该输出 'bbb'- 实现一个函数
find_min_max(),一个查找列表中最大和最小值,并返回一个元组.
print(find_min_max([1, 5, 3, 9, 2, 7])) # 应该输出 (1, 9)
print(find_min_max([-5, 0, 10, -10, 5])) # 应该输出 (-10, 10)7.2 参数
7.2.1 使用参数名
把参数传递给函数,可以按参数的顺序,也可以使用参数的名称
7.2.2 例:使用参数名称传递参数
def print_info(name, age):
print("姓名: ", name)
print("年龄: ", age)
print_info('Alex',20) # 按参数顺序:姓名,年龄
print ("------------------------")
print_info(age = 21, name = "Bob") # 按参数名,此时不用考虑参数的顺序常见的传参错误包括:少传参数、多传参数,或者给同一个参数同时使用位置传参和关键字传参。
print_info("Alex") # TypeError: 缺少 age
print_info("Alex", 20, "Shanghai") # TypeError: 多传了一个参数
print_info("Alex", name="Bob", age=20) # TypeError: name 得到了两个值7.2.3 默认参数
定义函数的时候,可以给某些参数定义一个默认值。
带默认值的普通参数应放在不带默认值的普通参数之后。
7.2.4 例:乘方函数(n次方)
def power(x, n=2): # n有默认值
return x ** n
print(power(5)) # 调用函数不传递n的值,使用默认值,结果为25
print(power(3, 3)) # 调用函数传递n的值,使用传递值,结果为277.2.5 参数进阶:位置专用与关键字专用
可以通过在函数签名中使用 / 与 * 控制调用方式:
def f(a, /, b, *, c):
# a 只能用位置传参;c 只能用关键字传参
return a + b + c
f(1, 2, c=3) # 合法
# f(a=1, b=2, c=3) # TypeError: a 不能用关键字传参
# f(1, 2, 3) # TypeError: c 必须使用关键字传参7.2.5.1 可变默认参数陷阱
不要把列表、字典等可变对象作为默认参数,它们会在多次调用间共享状态:
def append_bad(x, acc=[]): # 不推荐
acc.append(x)
return acc
print(append_bad(1)) # [1]
print(append_bad(2)) # [1, 2] 共享了上次的结果正确写法:用 None 作为占位,在函数内创建新对象。
def append_ok(x, acc=None):
acc = [] if acc is None else acc
acc.append(x)
return acc7.2.6 打包(packing):处理不定数量的参数
打包位置参数
函数可以接受任意多个参数,例如求最大值的函数max()
print(max(1,6,2))
print(max(4,1,5,2))你要写一个这样的函数,那么可创建一个新的参数,前面带一个*号。那么不在参数列表里的参数,会组成一个tuple,并且绑定带这个带*号的变量名。
# 第一个参数是class_id,从第二个参数起,不定数量个参数,都会组成一个tuple,并命名为`students`(没有*)
def print_students(class_id, *students):
"""打印班级号,和同学的姓名"""
print("班级:",class_id)
print("学生包括:", students)
# 也可以逐一打印
print("学生包括:")
for s in students:
print (s)
print_students(5 ,"Alex","Bob","clare")实际上,如果你有可变参数的函数,如print_students,但是你拿到的数据是一个List,怎么办?
直接写法:把列表元素一个个取出来,传给函数
students_list = ["Alex","Bob","clare"] # 这已经是一个list
print_students(5, students_list[0],students_list[1],students_list[2])当然,也简单的办法,变量在传递给函数时,前面加个*,python会自动帮你拆开
students_list = ["Alex","Bob","Clare"] # 这已经是一个list
print_students(5, *students_list) # 自动把students_list这个List,拆成多个元素打包关键字参数
类似地,也允许函数接受任意数量的关键字参数(按参数名称传递),这些参数会被收集到一个字典中。
def print_info_flexible(name, **other_info):
print(f"姓名: {name}")
for key, value in other_info.items():
print(f"{key}: {value}")
print_info_flexible("Alice", age=30, city="New York", occupation="Engineer")
# 姓名: Alice
# age: 30
# city: New York
# occupation: Engineer7.2.7 小练习
- 利用不定数量参数,写一个函数
my_sum(),可以求任意个变量的和。效果应该如下:
my_sum(1,2,3,4) == 10
my_sum(3,4,5) == 127.2.8 拆包(unpacking):把数据结构拆散传给参数
你定义了一个函数,其中每一个参数都有明确的含义,而函数的参数保存在一个List、Tuple里(比如第一个元素对应第一个参数,第二个元素对应第二个参数等等)或者Dict里(key就对应参数名),把这些数据结构中的元素,当参数传给函数。
- tuple或者list前面加
* - dict前加
**
称之为拆包(unpacking)
例:
def add(x, y):
print(f'x是{x},y是{y}')
return x + y
# 不使用拆包的写法
params = dict(x=1,y=2)
print(add(params['x'],params['y']))
# 拆包
params = dict(y=2,x=1) # 注:参数名一一对应,而非顺序。
print(add(**params))
#
params = [1,2] # 第一个元素对应第一个参数
print(add(*params))
params = (2,1) # 第一个元素对应第一个参数
print(add(*params))
# 当然,这样也是一样的
print(add(*[1,2]))7.2.9 多返回值与解包
Python 函数可以一次返回多个值(本质是返回一个元组),可在调用处解包:
def split_pair(x: int) -> tuple[int, int]:
return x, x**2
a, b = split_pair(3)
print(a, b)
# 解包长度不匹配会抛出 ValueError
# a, b, c = split_pair(3) # ValueError: not enough values to unpack- 注意和上一节的不同:定义函数的时候参数名是否带有星号?
7.3 参数作为可变类型和不可变类型
前面提到,多个变量名指向同一个可变对象(例如List,Dict),针对其中一个变量的修改,会引起所有指向同一个数据的变量都发生改变。
把List等,作为参数传递给一个函数,也有类似的后果。因此:
- 当不可变类型(如数字、字符串、元组)作为参数传递时,函数内部对参数的重新赋值不会影响到函数外部的原始变量,因为这实际上是在函数内部创建了一个新的局部变量。
- 当可变类型(如列表、字典)作为参数传递时,函数内部对该参数内容的修改(例如 list.append() 或修改字典的键值对)会影响到函数外部的原始变量,因为函数内外的变量名指向的是内存中的同一个对象。如果想避免这种情况,应在函数内部创建该对象的副本(如使用 list.copy() 或 dict.copy())再进行操作。
下例中,
- 把a_list作为参数x,传递给函数
do_change(x),那么在函数内部,变量x和外部a_list指向的是同一个数据,或者说,x成了a_list的别名。 - 把x作为函数的返回值,返回到外层,并赋予b_list,那么b_list, x, a_list,三个名字,实际上都指向了内存中的同一块数据。
- 当然,x只在函数体内可见。
a_list = list('apple') # a_list -> ['a', 'p', 'p', 'l', 'e']
def do_change(x):
x[0] = 'B'
return x
b_list = do_change(a_list) # 把a_list作为参数,则函数的参数 x -> a_list
print(b_list)
print(a_list)同样,如果你的设计意图并非“原地修改”,原变量必须保持不变,则可以把x拷贝一份。
a_list = list('apple') # a_list -> ['a', 'p', 'p', 'l', 'e']
def do_change(x):
y = x.copy() # 把x拷贝一份,对y进行修改,那么x就保持不变了
y[0] = 'B'
return y
b_list = do_change(a_list) # 把a_list作为参数,则函数的参数 x -> a_list
print(b_list)
print(a_list)这里的 copy() 是浅拷贝。如果列表或字典内部还嵌套了其他可变对象,内部对象仍可能被共享。嵌套结构需要单独处理,或者使用 copy.deepcopy()。
若传递的参数是不可变类型,如int,str等,则不能原地修改这个对象。函数内部的赋值只是让局部变量名指向一个新对象,不会影响函数外部的原变量。
7.4 在推导式中使用函数
回忆列表推导式的一般形式:选出符合条件condition的i,然后对i进行某个操作do_something(i),最后把结果集合成一个列表
[do_something(i) for i in a_list if condition(i)]
其中我们要对i进行的操作,可以是一个函数(推荐写出清晰的文档字符串与类型标注,便于后续维护与 IDE 辅助)。
比如,我们要把一个列表中的值进行一个很复杂的运行,可以首先把这个运算写成一个函数。这里以乘以2为例。
def do_double(x: int) -> int:
"""这里用乘以 2 代表示例运算"""
return x * 2
do_double(3)那么,用这个函数来处理列表中的每一个元素,列表推导式会每一个i交给函数,然后把函数的返回值组合成新的列表。
a = [1,2,3,4,5]
[do_double(i) for i in a]7.4.1 小练习
- 写一个函数
work(),要求接受一个字符串的List作为参数,把List中的每一个字符串,去掉第一个字符和最后一个字符,然后转为大写。
应该的效果:
work(['apple','banana','orange']) == ['PPL','ANAN','RANG']提示:
- 写一个函数,用于处理1个字符串
- 用列表推导式处理整个列表
- 把上述代码包装在
work()中
7.5 变量作用域
你在函数里调用了一个变量名,python会“从里到外”找这个变量,顺序是LEGB
LEGB含义解释:(暂时不用管)
- L-Local(function)即局部名称;函数内的名字空间
- E-Enclosing function locals即函数中嵌套函数的外部;外部嵌套函数的名字空间(例如closure)
- G-Global(module)即全局名称;函数定义所在模块(文件)的名字空间
- B-Builtin(Python)即内置名称;Python内置模块的名字空间
7.5.1 局部作用域
a = 10 # 全局变量a
def func():
a = 20 # 局部变量a。在定义了局部变量a之后。后面使用a这个变量名,将会首先找到这个变量(即从里到外找)
print(a) # 应该是20
func()a = 10 # 全局变量a
def func():
print(a) # 在函数内部,没有变量a,那么就往外一层找,因此会找到全局变量`a`,应该等于10
func()注意: 函数內部和外部变量重名的情况,要额外小心。因此第二个例子可能是你“忘记了在函数内部定义 a”,而不是你想要“引用全局变量 a”,但是因为有一个全局的变量 a,所以忘记定义 a 这个问题可能会被隐藏。
7.5.2 全局作用域
特别地,函数内部的赋值语句,其中的变量会被python看作一个local变量,如果内部未定义,就可能出错。
因为Python在编译函数的字节码时,只要发现函数内部有对变量的赋值操作(如 a = ...),就会默认该变量是局部变量,除非显式声明为 global 或 nonlocal。
a = 100 # 全局变量a
def func():
a = a + 1 # a + 1这个a系统认为是局部变量,但这个函数没有局部的a
print(a) # 全局变量a
func()UnboundLocalError: local variable 'a' referenced before assignment所以,如果你明确地要用一个函数外的变量,那么可以使用global关键字
a = 100 # 全局变量a
def func():
global a # 说明:a这个变量名,指向的是全局变量a
a = a + 1
print(a) # 全局变量a
func()7.5.3 nonlocal(修改外层局部变量)
nonlocal 用于修改“外层函数的局部变量”。它不同于 global(修改模块级全局)。
def outer():
x = 0
def inner():
nonlocal x
x += 1
return x
return inner
counter = outer()
print(counter()) # 1
print(counter()) # 27.6 递归简介(进阶)
递归:函数自己调用自己调用自己调用自己调用自己 …
例子,阶乘\(n! = n \times (n-1) \times (n-2) ... 2 \times 1\)。这里先讨论正整数的阶乘。
如 \(5! = 5 \times 4 \times 3 \times 2 \times 1\)
普通写法
def f(n):
result = n
for i in range(1, n): # 注意,range(1,n),只到 n-1
result *= i
return result
result = f(5)
print(result)递归的写法
\(f(n) = n * f(n-1)\)
\(f(n - 1) = (n - 1) * f(n - 2)\)
\(f(n) = n * (n - 1) * f(n - 2)\)
def f(n):
if n == 1:
return 1 # 递归终止条件
else:
return n * f(n-1) # 递归:自己调用了自己
result = f(5)
print(result)7.7 函数式编程(进阶)
下面介绍几个和函数有关的常用工具。这些工具通常归在函数式编程 (Functional Programming) 这一类内容中。
函数式编程强调:
- 纯函数 (Pure Functions):函数的输出完全由其输入决定,且没有副作用。
- 不可变性 (Immutability):数据一旦创建,就不应被修改。
- 高阶函数 (Higher-Order Functions):函数可以接受其他函数作为参数,或者返回一个函数。
本节介绍以下内容:
map()和filter():对序列中的元素逐个处理或筛选。- 匿名函数
lambda:定义简单的匿名函数。 - 高阶函数的概念:函数可以作为参数,也可以作为返回值。
- (选学)
reduce():对序列进行累积计算。 - (选学) 闭包 (Closures):理解函数如何“记住”其创建时的环境。
7.8 map和filter
7.8.1 map
有一个List,a = [1,2,3,4,5],你现在要把其中的每一个元素都乘以2,并保存在一个新的List中。用现有的知识,可以这样
- 建立一个空的List用来保存结果
result = [] - 循环
a中的所有元素,并且乘以2,添加到result的末端
a = [1,2,3,4,5]
print(a)result = []
for i in a:
result.append(i*2)
print(result)map函数,可以把一个函数,应用到List中的所有元素上。
def do_double(x):
"""翻倍函数"""
return x * 2
print(do_double(3))把 do_double 函数,应用到列表 a 中的每一个元素里。
result = map(do_double, a) # 把 do_double 函数,应用到列表 a 中的每一个元素里。
print(list(result))也可用列表推导式
result = [i * 2 for i in a]
print(result)
result = [do_double(i) for i in a]
print(result)把a里的元素,全部转换为str
result = map(str, a) # 把str函数,应用到列表a中的每一个元素里。
print(list(result))7.8.2 filter
有一个List,a = [1,2,3,4,5],你现在要选出符合特定条件的元素,例如选出其中的奇数,组成一个新的List。用循环做:
a = [1,2,3,4,5]
result = []
for i in a:
if i % 2 == 1:
result.append(i)
print(result)和map一样,定义一个is_odd函数,作为filter的过滤条件,应该返回布尔值(True/False),作为是否符合条件的结果。
def is_odd(x):
return x % 2 == 1
print(is_odd(3))
print(is_odd(6))filter(判断函数, List)
result = filter(is_odd, a)
print(list(result))当然,也可以用列表推导式
[i for i in a if is_odd(i)]7.8.3 混合map和filter
选出a中的奇数,并乘以2
map 和 filter的做法
result = list(map(do_double, filter(is_odd, a)))
print(result)列表推导式的做法
result = [do_double(i) for i in a if is_odd(i)]
print(result)这其实可以理解为一个“数据流的概念”:
'''
a
-> filter by is_odd()
-> map by do_double()
-> result
'''- 列表
a首先经过filter函数的加工,然后再经过map函数的加工,最后得到result。 - 数据可以依次经过筛选、转换等步骤,最后得到处理后的结果。
注:
- 多数情况下,列表推导式和map/filter函数几乎可以相互替代
- 列表更加符合Python的“风格”
- 数据量很大时,
map/filter可能更合适:它们是 lazy(惰性)的,只有在你读取其中的值时,才会把函数真正应用上去。 - map/filter的结果,最后要转为list
所以
- 清晰性:列表推导式 ≥ map/filter 函数 > 循环(通常更符合 Python 风格)。
- 性能:内置函数/向量化(如
map搭配内建或 NumPy/Pandas)通常更快;列表推导式与map接近;纯 Python 循环最慢(但最直观)。以可读性为先,在有瓶颈时再做基准测试。
从逻辑上来讲,先看map/filter也有好处:把一个函数应用到List中的所有元素,或者按照条件过滤元素,是很常见的需求。Python 的列表推导式提供了更简洁的写法。
7.8.4 匿名函数 lambda
在使用map、filter,或者列表推导式时,如果要做的操作很短且含义清楚,并且可以写成一行(比如乘以二,或者取最后一个字母),可以直接使用匿名函数。
使用lambda关键字,一个表达式,直接返回这个表达式的结果,不用写return。
写法一般是:
lambda <参数列表>: <对参数的操作>
例如一个匿名版本的add(a,b)函数:
lambda a,b : a + b
或者一个匿名的翻倍函数:
lambda x: x * 2
以把一个列表所有元素翻倍为例:
用普通函数:事先定义了一个do_double函数,这个函数返回 x * 2
result = map(do_double, a)
print(list(result))用匿名函数:乘以2这类简单操作,用匿名函数即可,可以省下预先定义do_double函数。
result = map(lambda x : x * 2,a)
print(list(result))7.8.4.1 key 函数与排序/选最值
在排序或选最值时,常通过 key= 指定“比较的依据”。
items = [("alice", 3), ("bob", 5), ("carol", 2)]
print(sorted(items, key=lambda x: x[1], reverse=True)) # 按第二列降序
scores = {"alice": 92, "bob": 85, "carol": 97}
print(max(scores, key=scores.get)) # 选出分数最高的键注:
对于初学者,如果操作不够短、不够清楚,建议定义普通函数,并使用清楚的函数名。
7.8.5 map和filter的结果:惰性
如果我们直接打印map和filter的结果,我们会发现,它们的返回值不是一个List,而是一个map object或者filter object。
这是因为map和filter,不会在你调用map()/filter()函数的时候马上进行计算,而是在你读取其中的值的时候,才进行具体计算。我们称之为“惰性求值”。
例如,用前面的List翻倍的例子。
a = [1,2,3,4,5]
result = map(lambda x : x * 2,a) # 当你调用map的时候,并未真正地进行计算
print(result)所以,当你把map()/filter()函数的结果打印出来看的时候,python会告诉你,这是个map/filter object,即map/filter函数的结果。但是,里面具体的数据还没计算出来,所以没法直接使用
要用,很简单,用list()函数转换为一个列表即可。
print(list(result))当然,如果你使用列表推导式,那么结果直接就是一个List。
result = [i * 2 for i in [1,2,3,4,5]]
print(result)对于filter函数也一样:返回的不是列表,需要你手动转换。
def is_even(x):
return x % 2 == 0
# 过滤出偶数
print(list(filter(is_even, [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])))7.9 高阶函数
在Python中,函数是一等公民(头等函数,first-class function)。
一个函数,可以和任何变量或者对象一样,绑定一个名字(函数名),也可以换一个名字(重绑定),也可以作为参数传递给另一个函数(函数作为参数传另一个函数),也可以作为一个函数的返回值(函数返回另一个函数)。
7.9.1 函数是一等公民
def add(x,y):
return x + y
print(add(1,2))函数和变量一样,其名字也可以重新绑定.
dda = add之后,dda和add指向同一个函数(加法函数),dda()也可以正常调用。
dda = add
print(dda(1,2))7.9.2 函数作为参数
例如map,可以把一个指定的函数,应用到List的每一个元素上。
map()函数的第一参数,就是你要应用到List元素上的函数, 比如前例中乘以2do_double,这里是把函数do_double作为参数传递给了map。第二个参数,就是你要处理的List。
result = map(do_double, [1,2,3,4,5])
print(list(result))7.9.3 返回函数的函数(进阶)
用参数来生成不同的函数。
例如,我们写一个函数,用于求一个数x的n次方。可以先写成下面这样。
def power(x,n):
return x ** n例如,3的平方:
print(power(3,2))例如,2的3次方:
print(power(2,3))平方、三次方等等,非常的常用,我们想写个专门的函数,可以少输入一个参数
def square(x):
return power(x,2)
print(square(3))同样,三次方也是
def cube(x):
return power(x,3)
print(cube(2))我们看到,这2个函数,函数体几乎完全一样,只有1个地方不同:2和3。
- 如果某些场合,4次方也很常用,我们可以原样建立一个4次方函数。
- 但是,这些函数只有1个地方不同,可以把不同的指数作为参数。
这个函数可以根据参数n,返回另一个函数:用于计算n次方的函数。
def make_power_function(n):
def func(x):
# return power(x, n) # 也是一样的
return x ** n
return funcmake_power_function是一个函数,这个函数会返回另一个函数func
'''
约等于以下代码
def func(x):
n = 2
return x ** n
square = func
'''
square = make_power_function(2)cube = make_power_function(3)print(square(3))
print(cube(2))7.9.4 reduce (进阶)
reduce和map一样,不单是一个具体的函数,同时也是“一种常用的操作”,所以放在大部分编程语言中,都有相同的含义。因此一般会与map并列,常称之为map/reduce。
和map一样,reduce同样可以把一个函数应用到一个列表上,区别在于,你使用reduce的时候,你要运用的函数,例如func(x,y),有2个参数。
reduce会这么做:
- 取出你要处理的列表的头2个元素(
a[0]和a[1]),传进func(a[0], a[1])中,并得到一个返回值,如z1 - 取出列表的第3个元素
a[2],和前一个结果,一起传入func(z1,a[2]),得到一个返回值,如z2 - 取出列表的第4个元素
a[3],和前一个结果,一起传入func(z2,a[3]),得到一个返回值,如z3 - …
例如,我们对一个列表a = [1,3,5,7,9],reduce一下应用我们前面写的add()函数。
这个操作大致如下。
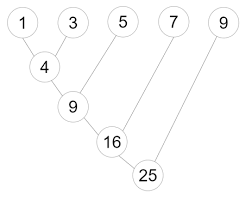
reduce函数在functools模块中,模块我们后面会讲。要引入reduce函数,使用这行代码:
from functools import reduce
from functools import reduce
a = [1,3,5,7,9]
reduce(add,a)7.9.5 闭包Closure(进阶)
闭包(closure)是函数及其引用的外层变量共同形成的对象。
例如
def make_power_function(n):
def func(x):
# return power(x, n) # 也是一样的
return x ** n
return func这个代码里,调用make_power_function()函数,会返回另一个函数func()。
这个函数里面调用了变量n,但n不在func()的函数体内,而在上一层。func()会保留它引用的外层变量。本例中,func()保留了n。
这段代码发生了什么?
square = make_power_function(2) square函数相当于一个保留了n=2的func()函数。
make_power_function(2),其中n = 2- 在
make_power_function()函数的内部,func(x)是可以看见这个n=2的 return func的时候,会把n=2,一并返回到外层square = make_power_function(2),此时我们把square这个名字,绑定给func这个函数(闭包),而后者同时还附带了n=2
前面讲变量作用域,Python找一个名称,是从内到外
- L局部作用域:即函数体内。例如本例中
func函数的x - Enclosing function locals:函数中嵌套函数的外部:例如本例中
func函数的n - G全局:代码的最外层
- B内置名称:python的一些内置的名称,如
max函数
现在可知,python查找变量名,先找局部作用域(函数内部),再找闭包的附带数据,再找全局变量,再找python的内置名称。
7.10 本章小结
本章核心回顾:
- 函数的定义:使用
def关键字,包含函数名、参数列表、冒号和缩进的函数体。 - 参数传递:理解位置参数、关键字参数、默认值、
*args和**kwargs的用法。 - 返回值:使用
return语句从函数中返回结果;若无return或return后无值,则返回None。 - 作用域:LEGB规则决定了变量的查找顺序,
global和nonlocal(进阶) 关键字用于修改外部作用域的变量。 - 可变/不可变类型作参数:注意可变类型(如列表)作参数时,在函数内部的修改会影响外部原对象。
- 函数式编程初步:
map、filter用于对序列进行批量操作,lambda用于创建简单的匿名函数。
7.11 函数 vs 向量化(数据分析实务)
在数据分析中,优先考虑 NumPy/Pandas 的向量化、聚合与布尔索引,通常比编写 Python 层的 for 循环更简洁且高效:
import numpy as np
import pandas as pd
df = pd.DataFrame({
'a': [1, 2, 3, 4],
'b': [10, 20, 30, 40]
})
# 列运算(向量化)
df['c'] = df['a'] + df['b']
# 条件列
df['flag'] = np.where(df['a'] > 2, 1, 0)
# 映射
code_to_cat = {1: 'X', 2: 'Y', 3: 'Z', 4: 'Z'}
df['cat'] = df['a'].map(code_to_cat)
# 分组聚合
g = df.groupby('cat')['b'].agg(['mean', 'sum'])提示: - np.vectorize 只是语法糖,不会带来显著加速。 - DataFrame.apply(axis=1, ...) 逐行运算通常较慢,应优先列运算或矢量化方案。
7.12 常见错误速查
- UnboundLocalError:在函数内赋值导致变量被视为局部,引用前未赋值;用
global/nonlocal明确意图。 - TypeError(参数不匹配):缺少必需位置参数、传多了参数,或对同一参数传了多个值(既位置又关键字)。
- 可变默认值陷阱:默认列表/字典在多次调用间共享;使用
None作为占位并在函数内创建新对象。 - 忘记调用函数:写成
func而非func(),得到函数对象而不是返回值。 - 返回值为 None:遗漏
return或分支未覆盖,后续参与计算报错。 - 解包长度不匹配:返回数量与左侧变量数不一致,抛
ValueError。 - lambda 晚绑定:循环内创建的 lambda 捕获同一变量,执行时取最终值;可传默认值参数规避。
- map/filter 惰性:未消费或未
list(...)转换,看不到结果。 - 关键字专用/位置专用:错误传参导致
TypeError,注意def f(a, /, b, *, c)的规则。