#%% 列表List
numbers = [1, 2, 3, 4, 5, 6]
letters = ["a", "b", "c", "d"]
print(numbers)
print(letters)5 基本数据结构
在上一章,我们学习了Python的基本“词汇”——单个的数字、文本(字符串)和逻辑值(布尔型)。然而,在现实世界的数据处理中,我们很少只跟单个数据打交道。我们常常需要处理一整个班级的学生名单、一张购物小票上的所有商品、或者一个用户的所有个人信息。
为了有效地组织和管理这些集合数据,Python提供了几种内置的数据结构。它们就像是不同类型的“容器”,可以把多个数据项(元素)按照特定的方式存放起来。
本章我们将探索Python中最常用的四种基本数据结构:
- 列表 (List): 像一个可以随时添加、删除或修改项目的有序清单。非常灵活,用途广泛。
- 元组 (Tuple): 类似于列表,但一旦创建就不能修改。像一个“只读”的有序清单,用于存放固定不变的数据。
- 集合 (Set): 一个不包含重复元素的无序(概念上)容器,适合用来去重或进行成员关系测试。
- 字典 (Dict): 存储键-值对 (key-value pairs) 的集合,就像一本真正的字典,可以通过“键”(如单词)快速查找对应的“值”(如释义)。非常适合存储具有映射关系的数据。
学完本章,你将能够:
- 创建和使用这四种基本数据结构来存储和组织数据。
- 理解它们各自的特点(如有序/无序、可变/不可变、唯一性等)和适用场景。
- 掌握访问、添加、修改和删除这些结构中元素的基本操作。
- 熟练运用列表的切片技术来获取子序列。
- 理解可变与不可变结构在赋值和拷贝时的重要区别,避免常见的陷阱。
掌握这些基本数据结构是进行任何稍复杂的数据处理和分析任务的基础。它们是你未来学习更高级数据分析库(如Pandas)的重要基石。
Note
本章内容较多,可以按两个层次学习。
必修主线:四种基本数据结构的创建、访问和常用操作
- List 创建、索引和负索引
- List 修改、添加和删除
len()、max()、min()、sum()sort()和sorted()inpop()、clear()、reverse()- List 切片,包括步长和反向切片
- Tuple 创建、访问、不可变,以及与 List 互转
- Set 创建、去重、空集合、不可索引和成员判断
- Dict 创建、访问、修改、添加和删除
keys()、values()get()和 key 是否存在- Dict 遍历
.items()
进阶学习:数据结构的补充操作和常见陷阱
count()、index()all()、any()sorted(..., key=...)和lambda- 切片赋值
- List 拷贝、浅拷贝和深拷贝
- 为什么用 Tuple,不用 List
- Tuple 作为 Dict 的 key,以及可哈希的含义
- 集合运算
- Set 和 List 的成员测试复杂度
dict.update()、pop()、popitem()、setdefault()zip()构造字典- 字典推导式
- Dict 别名与拷贝
5.1 列表List
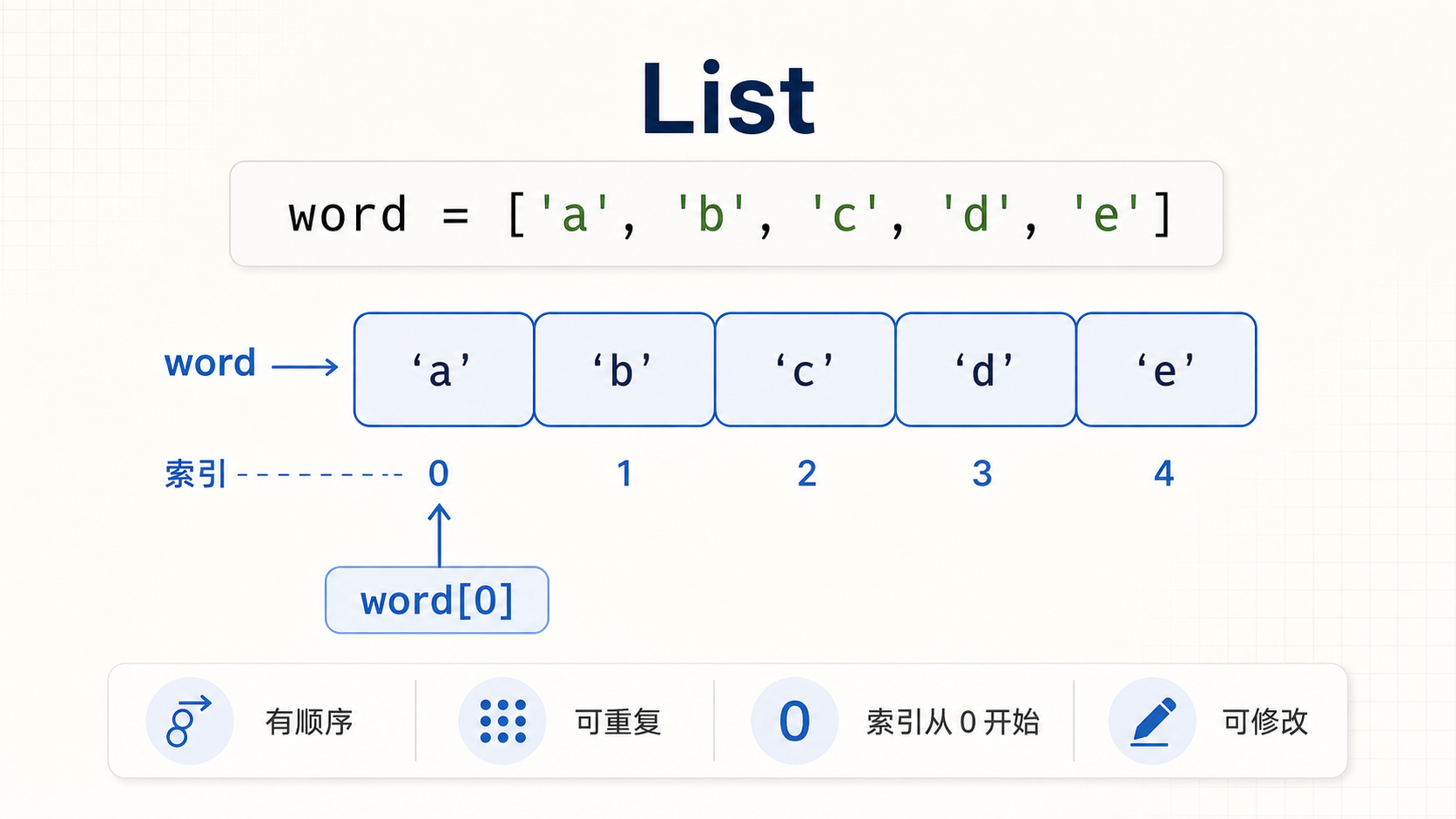
一个列表List,就是把几个元素(items),用一个固定的顺序连在一起的数据结构。列表List是一个重点,超级常用,内容比较多。
5.1.1 列表的创建
创建一个列表,可以用中括号[],其中每一个元素用逗号分开。
为了好看,建议每个逗号后加一个空格。
列表中的元素,可以混合多种类型。 但一般不建议这么做。
a_list = [1, 2, 3, "a", "b", "c"]
print(a_list)也可以+拼接两个List来创建新的List
a_new_list = [1,2,3] + [7,8,9]
print(a_new_list)我们还可以创建空List。比如,当列表的第一个元素还没确定,而你要先行创建列表,然后再生成元素添加进去。
#%% 空列表
empty_list = []
empty_list = list()
print(empty_list)对一个字符串String 使用list()函数,可以把字符串分解成字母组成的List。这本质上就是类型转换:用类型的名字做转换函数的名字。
如果把函数名list看成是一个动词,或者可以解释成:list a string。
#%%
print(list('apple'))注意:实际上,list()可以用于所有类型的序列(有序列结构的其他数据),以后我们遇到再说。
特别地,如果我们转换一个多行的字符串,会发现什么?
a = '''hello
python
'''
print(list(a))注意,换行符\n也出现在其中。实际上,应该把换行符之类的不可见字符也看成一个真正的字符,实际上存在,但部分情况不可见而已
5.1.2 列表的元素
要引用一个列表的元素,也使用[],其中包括元素的索引(index),注意第一个元素的索引是0(Python 和 C 语言一样,从0开始计数)
print(numbers)
print(numbers[0])
print(numbers[3])可以反向引用元素,例如-1指向最后一个元素,-2指向倒数第二个,如此类推
print(numbers)
print(numbers[-1])
print(numbers[-2])列表中的元素是可变的。同样,用等号=对某个元素赋值即可
print(numbers)
numbers[0] = 999 # 修改第一个元素的值为999
print(numbers)添加元素
在List的最后添加元素可以用.append()。添加多个元素,可以用.extend()。初学时,可以先把要添加的多个元素放进一个list里,再交给extend。插入元素到指定索引号.insert()
letters = list("abcd")
print(letters)
letters.append('e')# 添加一个元素
print(letters)
letters.extend(['f','g']) #添加多个元素:把要添加的元素放进一个list里
print(letters)
letters.insert(3,"apple") #元素插入到指定索引的位置
print(letters)移除:移除某个元素,使用.remove();按照索引移除del
print(letters)
letters.remove('apple') # 如果'apple'不存在,会抛出错误:ValueError: list.remove(x): x not in list
print(letters)
del letters[0]
print(letters)5.1.3 其他常用操作
- 获取的List的长度
题外话:从长度可以知道,最后一个元素的索引号是长度-1
a = list("apple")
print(a)
print(len(a))- 获得最大值、最小值和求和
a = [1,2,3,4,5]
print(max(a)) # 如果包含不可比较大小类型,如str,会出错!
print(min(a))
print(sum(a))- 原地排序
.sort(),默认的排序方式是“从小到大”。与sorted()的区别在于:.sort()原地修改列表,而sorted()返回一个新的已排序列表。
注意:这个方法会改变原List的顺序
a = [5,3,4,2,1]
a.sort()
print(a)也可以逆序:从大到小
a.sort(reverse=True)
print(a)- 排序
sorted(),
注意:sorted()会返回一个新的、排序后的List,不会改变原List的顺序。
a = [5,3,4,2,1]
print(a)
print(sorted(a)) # 打印排序的结果
print(a) # 原list的顺序并未改变也可以逆序排序(从大到小)
b = [3,4,5,1,2]
print(sorted(b, reverse=True))- 统计某个元素的数量
.count()
a = [1,2,2,2,3,3,5,5,5,5,5]
print(a.count(3)) # a中的3有多少个?- 查找某个元素第一次出现的索引
a = list('an apple')
print(a)
print(a.index('p'))- all和any
可以用来回答“是否全班同学都及格?”之类的问题。这部分我们在后面列表推导式会进一步展开。
# 是否全部为真
a = [True, True]
print(all(a))
# 是否有任何一个元素为真
b = [False, True]
print(any(b))- 判断in 某个元素是否在一个列表中
a = [1,2,3,5,6]
print(3 in a)
print(4 in a)- 弹出并删除元素:
pop()(默认末尾,或指定索引)
a = [1,2,3,4]
last = a.pop() # 删除末尾,返回 4
first = a.pop(0) # 删除索引0,返回 1
print(a, last, first)- 清空列表:
clear()
a = [1,2,3]
a.clear()
print(a)- 原地反转:
reverse()(与切片a[::-1]的区别是是否原地)
a = [1,2,3]
a.reverse()
print(a)- 排序的高级用法:按键
key=与reverse=
words = ['apple','kiwi','banana']
print(sorted(words, key=len)) # 按长度
print(sorted(words, key=lambda s: s[-1])) # 按最后一个字母小思考:如何判断一个元素是否“不在一个列表中”呢?
5.1.4 List 练习(元素和常用操作)
创建一个名为my_list的列表,包含以下元素:1, 3, 5, 7, 9。然后创建一个变量element,将其赋值为列表中的第四个元素。
创建一个名为my_list的列表,包含以下元素:2, 4, 6, 8。使用append方法将10添加到列表的末尾,然后创建一个变量length,将其赋值为列表的长度。
创建一个名为my_list的列表,包含以下元素:1, 9, 3, 7。使用insert方法在9和3之间插入一个值为5的元素,然后创建一个变量max_value,将其赋值为列表中的最大值。
创建一个名为my_list的列表,包含以下元素:2.2, 3.3, 1.1, 4.4。使用remove方法删除元素1.1,然后创建一个变量min_value,将其赋值为列表中的最小值。
提交范例:
注:不用把题目抄一遍
# Class:你的班级
# Id:你的学号
# Name:你的姓名
# List 练习1
# 练习题1
# <这里写第1题的代码>
# 练习题2
# <这里写第2题的代码>
# 练习题n
# ...5.1.5 List的切片
如何获取(或者修改)一个List中的某一段?
a = list('abcdef')
print(a)截取:从第2个元素开始到第4个元素:(正确答案应该是['b', 'c', 'd'])
写法是:a[起点 : 终点],且得到的结果是“包含起点,但不包含终点”
如: a[1:4]:切片起止点:包含起点(1号,即b),不包含终点(不含4号,即e)
print(a[1:4])可以不写起点或者终点,默认是到一边的尽头
print(a[:4]) # 4号元素之前(0,1,2,3)(不包含终点)print(a[3:]) # 3号元素以及之后(3,4,5)(包含起点)可以倒数切片:
如从倒数第二个元素开始到最后
print(a[-2:]) # 倒数第二个元素开始到最后(包含起点)从头切到倒数第二个元素(不含终点)
print(a[:-2]) # 从头切到倒数第二个元素(不含终点)切片赋值 : 直接覆盖原来的位置的值,可以不等长
a = list('abcdef')
print(a[2:4])注意:a[2:4]只有2个值,但我们替换成不等长的其他List,如替换3个值进去
a[2:4] = ['x','y','z']
print(a)这使得['c', 'd'] -> ['x', 'y', 'z']
赋予空列表,可以达到删除的效果。
a[2:5] = [] # x,y,z是2,3,4号
print(a)还可以按步长切片
a[起点:终点:步长]
步长默认为1(每个元素都取值),如果设置为2,每2个元素取一个值
a = list('abcdefgh')
print(f'''a is {a}
a[1:6] is {a[1:6]}
a[1:6:2] is {a[1:6:2]}
''')一个简单小技巧:步长也可以取负数,等于逆序取值。因此有一个简单的把列表逆序的方法: [::-1]
a = list('apple')
b = a[::-1] # 第一个冒号前后都没有值,表示取整个列表
print(a)
print(b)5.1.6 List 练习(切片和其他)
创建一个名为my_list的列表,包含以下元素:1, 2, 3, 4, 5。使用切片获取前三个元素,并存储在新列表first_three中。
创建一个名为my_list的列表,包含以下元素:1, 2, 3, 4, 5, 6, 7, 8, 9, 10。使用切片和步长来创建一个新列表even_numbers,其中包含my_list中的所有偶数。提示:这里的偶数值从索引1开始。
创建一个名为my_list的列表,包含以下元素:‘a’, ‘b’, ‘c’, ‘d’, ‘e’。使用切片创建一个新列表reversed_list,它是my_list的一个反转版本。
创建两个列表,名为list1和list2,分别包含以下元素:
- list1: [1, 2, 3, 4]
- list2: [5, 6, 7, 8]
使用切片和+操作符创建一个新列表merged_list,它包含list1的前两个元素和list2的后两个元素。
- 创建一个名为my_list的列表,包含以下元素:‘apple’, ‘banana’, ‘cherry’, ‘date’, ‘elderberry’。使用切片和列表连接,把中间的三个元素替换为三个新元素:‘fig’, ‘grape’, ‘honeydew’。
5.1.7 注意:List的拷贝 (*)
这部分可能有点抽象。
- 变量名是个标签
- 变量赋值,给内存中的一个数据“贴标签”
- 那用一个变量,给另一个变量赋值会如何?
以一个数字来举例
a = 123
print(a)
b = a
print(b)
a = 321
print(f'a is {a}\nb is {b}')中间发生了什么
a = 123
创建了一个整型对象,里面存放了123,把a这个名字绑定到这个对象上。
b = a
把a这个标签,所指代的对象,再贴一个标签b。这个时候,a和b都指向这个整型对象,里面存放了123。
a = 321创建了一个新的整型对象,里面存放了321,把a这个名字,重新绑定到这个对象上。
现在 a -> 321,b -> 123
但List比较特殊
以letters来举例:
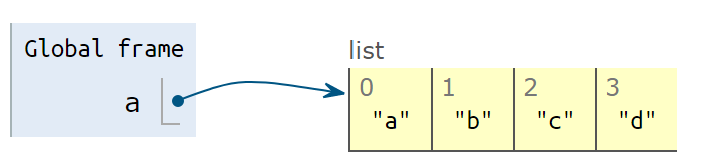
a = ["a", "b", "c", "d"]
print('a is ', a)- 变量
a指向["a", "b", "c", "d"]
b = a 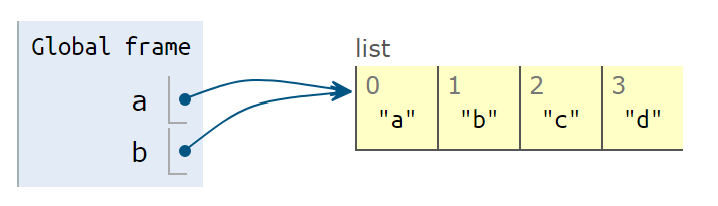
- 变量
b指向a相同的数据["a", "b", "c", "d"]
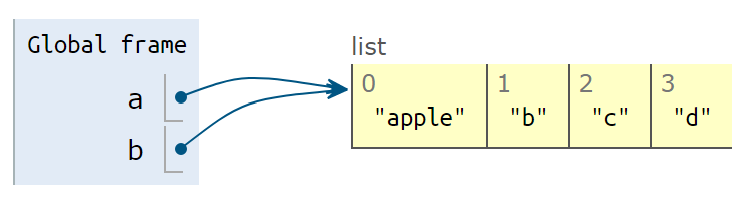
a[0] = 'apple'
print('b is ', b)- 你修改了列表
a的值,b的值也改变了!因为a和b一直指向同一个对象。
- 如果要避免这种情况,要明确地把
a复制一次,
a = ["a", "b", "c", "d"]
b = a.copy()
print(f'a is {a}\nb is {b}')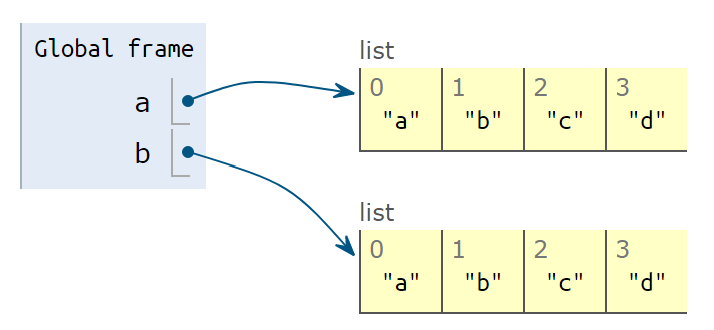
a[0] = 'apple'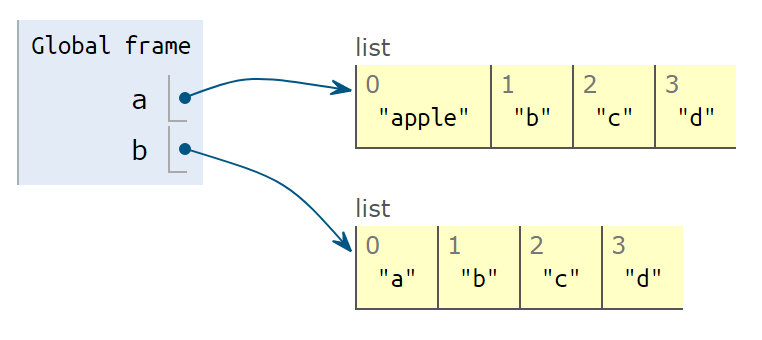
print(f'a is {a}\nb is {b}')这样就不会互相干扰了。
补充:拷贝列表的常见方式还有切片和构造函数,效果等同于 .copy()(都是浅拷贝):
a = [1,2,3]
b1 = a[:] # 切片拷贝
b2 = list(a) # 构造函数拷贝
b3 = a.copy() # 方法拷贝
print(b1, b2, b3)浅拷贝对嵌套列表并不能复制内层对象(仍然共享):
import copy
orig = [[1,2],[3,4]]
shallow = orig.copy() # 或 orig[:]
deep = copy.deepcopy(orig)
orig[0][0] = 999
print('orig =', orig)
print('shallow=', shallow) # 受影响
print('deep =', deep) # 不受影响总结:
- Number ,String,Tuple等,是“不可变类型”:不能原地修改对象;给变量重新赋值时,会创建或指向另一个对象,然后重新绑定变量名(转贴标签)
- List等,是“可变类型”:修改里面的值,其实是“原地修改”,导致所有指向这个数据的变量都发生改变。
- 要避免上述情况,请明确地复制原List一次。
5.2 元组Tuple

元组:同样是序列结构,可以视为“不可修改的列表”。准确地说,元组本身一旦创建,就不能再增加、删除或替换其中的元素。
注意:如果元组里面放的是List,那么“元组中的这个位置指向哪个List”不能改,但这个List本身仍然可以被修改。初学阶段一般先避免在元组中嵌套可变对象。
5.2.1 元组的创建
和List类似,但使用小括号创建。
注意,从打印的结果也可以看出,()表示元组,中括号[]表示列表。
a = (1,2,3,4,5)
print(a) # 元组
b = [1,2,3,4,5]
print(b)如果元组只有1个元素,必须加一个逗号,,以避免 Python 认为这是个运算。
a = (1,) # 正确的做法,识别成元组
print(a)
b = (1)
print(b) # 会被识别成一个数字也可以不用小括号,只使用逗号创建(为了维持代码的清晰和可识别,不建议这么做。)
a = 1,2,3,4,5
print(a)5.2.2 访问元组的元素
访问元组的方法和List完全一样,可以照搬。
但是“可读不可写”,不能做任何修改或删除。
a = (1,2,3,4,5) # 读取元素和获得切片等,和List完全一样
print(a[3])
print(a[2:4]) a = (1,2,3,4,5)
a[3] = 999 # 要对元组的值进行修改,会报错TypeError: 'tuple' object does not support item assignment5.2.3 元组和列表的互转
List和Tuple用非常接近的结构,互相转换只要用前述的“简单类型转换”方法即可
a_list = list('apple') # str转为list
a_tuple = tuple(a_list) # list转为tuple
print(a_tuple) # 注意,打印的结果是()小括号a_tuple = (1,2,3,4,5) # 创建一个tuple
a_list = list(a_tuple)
print(a_list)5.2.4 为什么要用tuple,不用list?
Tuple只有List的一半能力(只能读,不能改),只用List也可以完成Tuple的所有功能,那用Tuple有何意义?
- List可能被意外修改,但Tuple不会
如前述,List是一个可变类型,可以有不止一个变量名指向同一个List数据。所以,使用List保存的数据,可能会在传递的过程中,在不经意间被你的某些代码所修改,比如忘记.copy()。
如果一个列表结构的数据,原则上不应该被改变,则可以采用Tuple。如果被代码意外修改,则会报错通知你。
Tuple一般会比List节约内存,但我们一般不必考虑这一点。
Tuple在一定条件下可以用作Dict的Key(后面会说)
因此一般而言,大部分情况下用来作为“数据不应被修改的序列结构”即可。
5.3 集合Set
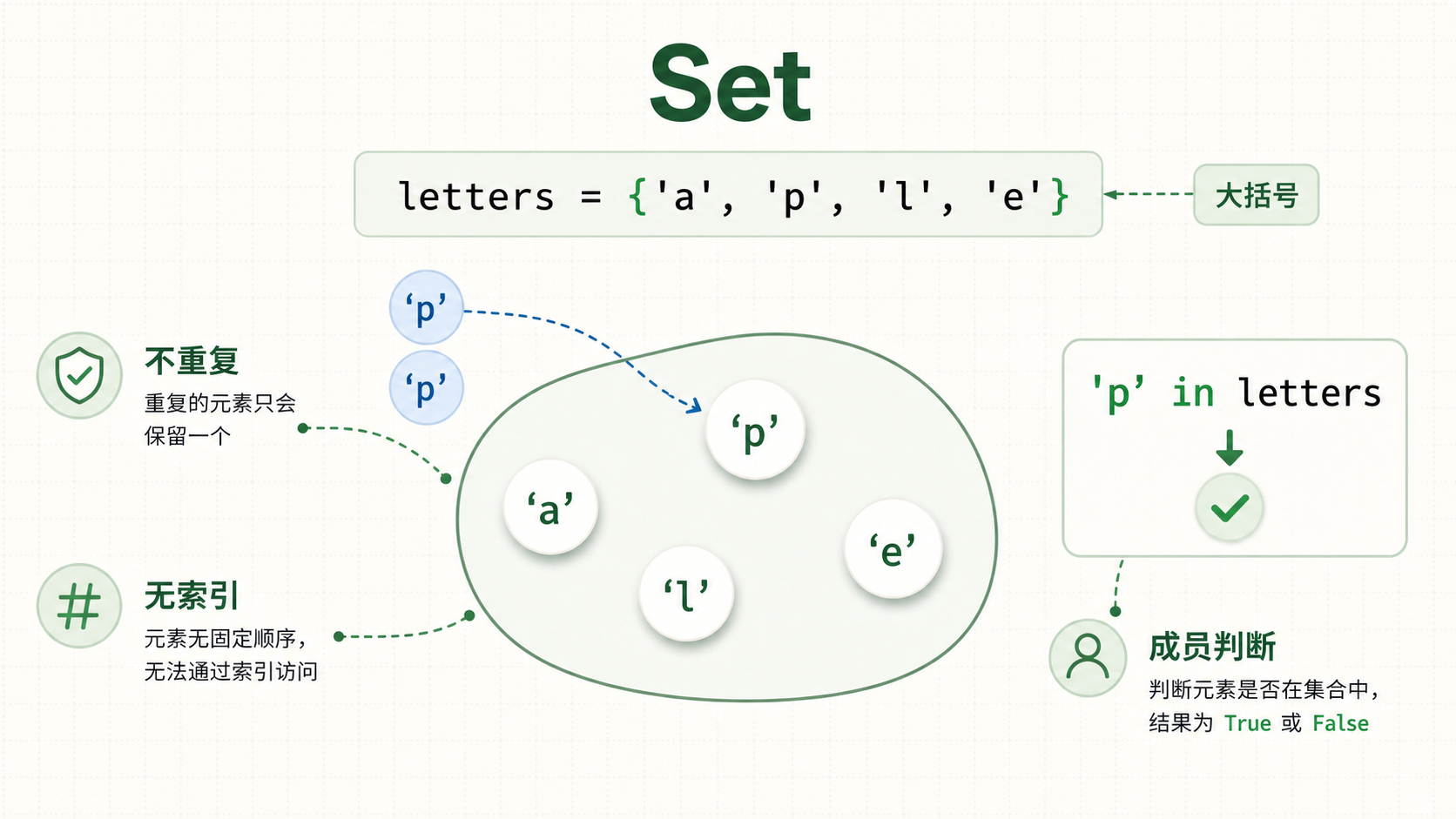
一个无序的、元素不重复的数据结构。非空集合通常用{}创建。
a = {1,1,2,3,4,4,5} # 创建一个集合
print(a)注意:集合中的元素不会重复。
5.3.1 空集合与不可索引 (*)
- 创建空集合需使用
set();{}表示空字典:
print(type({})) # 空字典
print(type(set())) # 空集合- 集合是无序、不可下标访问的数据结构,不能用
a[0]:
a = {1, 2, 3}
a[0]TypeError: 'set' object is not subscriptable5.3.2 简单集合运算
这里只简单介绍,后续用到再深入。
- 并集,用
.union或者|
A = {1,2,3}
B = {3,4,5}
# 并集
print(A.union(B))
print(A|B)- 交集:
.intersection()或者&
print(A.intersection(B))
print(A & B) - 差集:
.difference()或者-
print(A.difference(B))
print(A - B) - 对称差:
.symmetric_difference()或^(属于其中一个集合但不同时属于两个)
print(A.symmetric_difference(B))
print(A ^ B)- 子集/超集判断:
issubset/issuperset
print({1,2}.issubset(A))
print(A.issuperset({1,2}))- 成员测试复杂度:
in对 set 为近似 O(1),对 list 为 O(n)。 简单理解:用in来检查set,大部分情况下耗时是常数,和set的size无关,但如果用来检查list,则耗时和list的size成正比。
5.3.3 其他 (*)
一个小技巧:如何去除list中的重复元素?转为set再转回list。注意:转换为Set之后,其中元素的顺序就不保证了。
a = list('apple')
print(a)
b = list(set(a))
print(b) # 顺序不保证和a相同如果希望“去重且保持原有顺序”,可以使用:
a = list('apple')
print(list(dict.fromkeys(a))) # ['a','p','l','e'],顺序按首次出现5.3.4 Set 小练习 (*)
- 给定列表
ids = [101,102,102,103,104,101],去重得到唯一客户集合,并判断105是否在其中。 - 设
A = {'a','b','c'},B = {'b','c','d'},分别求并集、交集、差集、对称差。 - 判断
{1,2}是否为{1,2,3}的子集,并判断{1,2,3}是否为{1,2}的超集。 - 比较两种去重方式的差异:
list(set(seq))与list(dict.fromkeys(seq)),在seq = list('abcaabbcc')上分别输出结果并比较顺序。
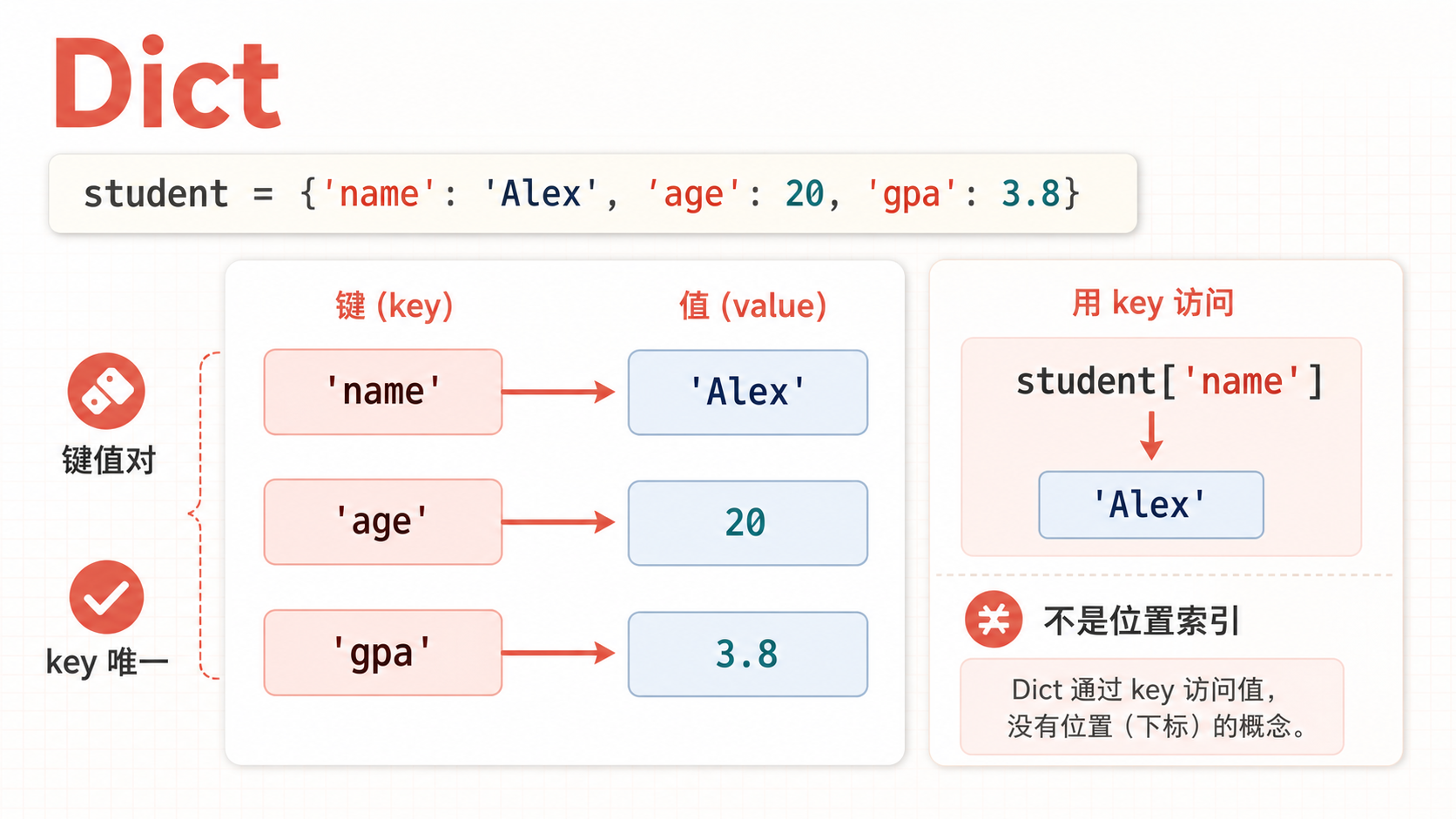
5.4 字典Dict
- 和List或者Tuple类似,dict是很多数据的集合体
- Python 3.7之后,dict中元素的顺序就和加入时候保持一致。现在主流的Python版本一般都会满足。
- dict中的元素访问,是通过”键key”访问,一个key会对应一个value。
- key必须是可哈希(hashable)的类型。常见的例子有string、int,或者内部元素也都可哈希的tuple。
- 和List一样,dict可以存放不同类型的数据
- key是唯一的,如果对一个key赋予不同的值,那么新的value会替换旧的value.
这和新华字典类似:
- 通过这个字的拼音(即key),找一个字的含义(value)
- 不能通过“第几个(索引)”来访问字典,只能通过 key 访问;若确需按插入顺序取“第 i 个”键,可用
list(d)[i](不推荐在业务逻辑中依赖此方式)。
5.4.1 创建dict
使用大括号,key:value的方式,key-value之间使用逗号分隔
{key1:value1, key2:value2, ... }
例如同学的个人信息:姓名、年龄、专业、绩点(GPA)等。
我们使用这些信息的名称作为 key,对应的具体内容作为 value。这样就可以通过“键名”快速查到对应的信息。
# 一个学生的个人信息
student = {"name": "Alex", "age": 20, "major": "Economics", "gpa": 3.8}
print(student)这背后是一组“名称 → 值”的映射关系:
"name" -> "Alex"
"age" -> 20
"major"-> "Economics"
"gpa" -> 3.8
也可以用 dict() 函数来创建,写法类似“按参数名赋值”:
student = dict(name="Alex", age=20, major="Economics", gpa=3.8)
print(student)5.4.2 访问字典数据
字典数据的访问,和List或者Tuple一样,都是用中括号[],但提供的不是数据的索引index,而是key(键名)。
# 访问姓名与专业
print(student['name'])
print(student['major'])修改其值也一样,直接赋值即可
# 修改绩点(GPA)
student['gpa'] = 3.9
print(student)实际上,添加键值的方法就是直接赋值
例如,新增一个联系方式(email):
student['email'] = '[email protected]'
print(student)同样,删除键值的函数是del,和删除一个变量一样。
删除刚才新增的 email。
del student['email']
print(student)5.4.3 获得所有的 key (*)
获得全部的key,使用.keys()方法。注意是复数,有个s。
print(student.keys())注意,.keys()方法返回的不是一个List,所以我们一般还是转为List,便于进行其他操作。转换也是直接采用list()函数即可。
keys = list(student.keys())
print(keys)5.4.4 所有的value (*)
获得全部的value,使用.values()方法。
print(student.values()) # 同样是复数,有个 s。同样,我们可以转换为List。
values = list(student.values())
print(values)5.4.5 其他操作
和List一样,dict也可以用len()函数获得数据的长度
print(len(student))5.4.6 更新与删除(常用方法) (*)
# 以同一个示例 student 展示常用方法
student = {"name": "Alex", "age": 20, "major": "Economics", "gpa": 3.8}
# 合并/更新:更新已有字段(gpa),并新增两个字段(city, hobby)
student.update({"gpa": 3.9, "city": "Shanghai", "hobby": "basketball"})
print(student)
# 删除并返回指定键对应的值
val = student.pop('city')
print(val, student)
# 弹出并返回“最后插入”的一对(此处是 'hobby')
key, val = student.popitem()
print(key, val, student)
# 若键不存在则设置默认值并返回
print(student.setdefault('email', '[email protected]'))
print(student)5.4.7 遍历字典 (*)
# 继续使用同一个示例 student 进行遍历演示
student = {"name": "Alex", "age": 20, "major": "Economics", "gpa": 3.9, "email": "[email protected]"}
for k in student: # 遍历键(等同于 student.keys())
print(k)
for k, v in student.items(): # 同时遍历键和值
print(k, v)
print('name' in student) # 成员测试检查 key 是否存在5.4.8 从序列构造与字典推导式 (*)
# 从两个序列构造一个学生信息字典
fields = ['name', 'age', 'major', 'gpa']
values = ['Alex', 20, 'Economics', 3.8]
student = dict(zip(fields, values))
print(student)
# 字典推导式:基于 student 构造派生信息
# 例1:值的字符串长度(数字也先转为字符串)
lengths = {k: len(str(v)) for k, v in student.items()}
print(lengths)
# 例2:仅保留数值型信息,并做简单变换(如 GPA 四舍五入到 1 位)
numeric_info = {k: round(v, 1) for k, v in student.items() if isinstance(v, (int, float))}
print(numeric_info)5.4.9 别名与拷贝
和List一样,如果用一个dict为另一个dict赋值,那么2个变量名会指向同一个数据,对其中一个数据的修改,会使得另一个变量中的数据也改变(毕竟只是同一个数据的2个名字)
要避免这一点,同样使用.copy()函数,拷贝一个dict。具体和List一样,这里不再重复。
5.4.10 不存在的key
如果我们直接读取一个不存在的key,会报错
student['nickname']key错误:即找不到 ‘nickname’ 这个 key
KeyError: 'nickname'但是,某些时候,我们想,如果key不存在,则返回一个默认值,而不要因为报错而中断程序。
这个时候可以使用.get()方法:如果key存在,则返回对应的value。如果不存在,则返回我们前面说过的None。
print(student.get('name')) # 获取一个存在的 key
print(student.get('nickname')) # 获取一个不存在的 key对于可能不存在的 key,我们也可以提供一个更合适的默认值。例如“没有设置昵称”时返回 "N/A"。
.get() 这个方法的第二个参数,是找不到 key 时使用的默认值。
print(student.get('nickname', 'N/A')) 5.4.11 key是否存在
判断一个key是否存在, 也是用in。
print('name' in student) # 'name' 是存在的
print('nickname' in student) # 'nickname' 是不存在的5.4.12 键-值对(items) (*)
通过.items(),dict中的键值对可以转换成一个类似List的结构:其中每一个元素,是一个(键-值)对,即(key, value)的元组。
student = {'name': 'Alex', 'age': 20, 'major': 'Economics'}
print(student)可以使用.items()这个方法,获取一个dict的所有(key, value)对。
print(student.items())当然,我们也可以转为一个真正的List用list()函数
all_items = list(student.items())
print(all_items)显然,这是3个(key, value)元组构成的List。
注意
- 最外层的中括号
[]:这是一个List - 每一个元素的小括号
():每一个元素是一个Tuple
看看第一个元素是什么?
print(all_items[0])易见,这就是一个(键名, 值)组成的元组,例如(‘name’, ‘Alex’)。
5.4.13 Dict小练习
- 题目1:创建字典 创建一个名为 person_info 的字典,其中包含以下键值对:
'name': 'Alice'
'age': 25
'city': 'New York'题目2:访问字典中的值 使用刚刚创建的 person_info 字典。编写一个Python语句来访问键 ‘age’ 对应的值,并将其存储在一个名为 age_value 的变量中。
题目3:添加键值对 在 person_info 字典中添加一个新的键值对,其中键为 ‘occupation’,值为 ‘Engineer’。
题目4:修改字典中的值 修改 person_info 字典中键 ‘city’ 对应的值为 ‘San Francisco’。
题目5:删除键值对和获取所有键 首先,删除 person_info 字典中键 ‘age’ 及其对应的值。然后获取该字典中所有的键,并将它们存储在一个名为 keys_list 的列表中。
5.5 本章小结
你现在已经掌握了Python中的几种核心数据结构。
核心要点回顾:
- 列表 (List
[]): 有序、可变的序列。支持索引、切片、添加 (append,extend,insert)、删除 (remove,del)、排序 (sort,sorted) 等多种操作。是Python中最灵活、最常用的数据结构之一。 - 元组 (Tuple
()): 有序、不可变的序列。一旦创建,不能增加、删除或替换元素。访问方式(索引、切片)与列表类似。适用于存储不应改变的数据;当内部元素也都可哈希时,也可以作为字典的键。 - 集合 (Set
{}): (概念上)无序、元素唯一的集合。主要用于去重和快速成员检查 (in),支持并集、交集、差集等数学运算。 - 字典 (Dict
{key: value}): 存储键值对的集合,现代Python中保持插入顺序。通过唯一的、可哈希的键来快速访问、添加、修改或删除值。.get()方法可安全地获取值。 - 切片 (
[start:stop:step]): 强大的序列(列表、元组、字符串)截取工具,记住“包含起点,不含终点”。 - 可变 vs. 不可变: 这是理解Python行为的关键。
- 可变类型 (List, Dict, Set): 可以原地修改。简单赋值 (
b = a) 会让多个变量指向同一个对象,修改一个会影响另一个。需要独立副本时,必须使用.copy()方法。 - 不可变类型 (Tuple, str, int, float, bool): 不能原地修改。对其操作通常会创建新对象。
- 可变类型 (List, Dict, Set): 可以原地修改。简单赋值 (
- 索引从0开始: 所有有序序列(列表、元组、字符串)的第一个元素索引都是
0。
5.6 常见错误速查
- NameError: 使用了不存在或拼写错误的变量名。优先检查变量名拼写、是否在使用前已正确赋值/定义(注意作用域)。
- IndexError: 访问了超出范围的索引(列表/元组)。检查长度
len(seq),确认最大索引为len(seq)-1,或先做空值/边界判断。 - KeyError: 访问了字典中不存在的键。先用
in判断或改用dict.get(key, default)提供默认值。 - TypeError:
- 试图修改元组(不可变类型)元素。改用列表或在修改前将元组转为列表。
- 将不可哈希的类型(如 list、dict)作为字典的键或集合元素。改用可哈希的等价写法;例如用内部元素也都可哈希的 tuple 表示固定序列。
- 在不支持的操作中混合不兼容类型(如包含 str 与 int 的列表直接
sort())。为其提供key=函数或先做类型清洗。
- ValueError:
list.remove(x)时x不在列表中。先用if x in lst:判断或使用更稳妥的逻辑。
- AttributeError: 在不支持的方法上调用(如对元组调用
append)。确认对象类型,查阅对应类型的有效方法。 - UnboundLocalError: 在函数内引用了尚未绑定的局部变量。考虑使用
global/nonlocal或在引用前先赋值。