Pandas 用来处理二维表格,类似 Excel 工作表:一行是一条记录,一列是一个变量。读入后得到的是一个 DataFrame 对象,可以继续做查看、筛选、生成新列、清洗、合并、分组汇总和重塑。
Anaconda 预装了 Pandas。如果 import pandas as pd 报 ModuleNotFoundError,说明 notebook 用的 Python 解释器不是课程指定的环境——回到环境配置部分检查解释器选择。
本章使用的数据放在工作目录下的 data 文件夹中。读取时用相对路径,例如 data/company_annual_operations_clean.xlsx。
前置知识
Jupyter Notebook 简介
本章使用 Jupyter Notebook。Notebook 文件扩展名是 .ipynb,适合记录数据分析过程:代码、文字说明和运行结果可以放在同一个文件中。
数据存放约定
本课程约定:数据文件都放在工作目录下的 data 文件夹中。工作目录可以理解为当前项目或当前 notebook 所在的主要目录。读取数据时,可以用相对路径引用文件,例如 data/company_annual_operations_clean.xlsx。
本章使用的数据
本章主要使用两张教学表:
data/company_annual_operations_clean.xlsx:干净的公司年度经营数据。一行是一家公司某一年的记录,包含公司名称、日期、行业、地区、资产、收入、利润、员工数等变量,用于练习单表操作。下载data/financial_indicators_dirty.xlsx:待清洗的公司年度财务指标数据。它和第一张表同样以公司和年份为核心,但故意保留了一些常见问题,用于练习清洗,并在清洗后与经营表合并。下载
- 创建ipynb文件,只要VS Code建立一个新的文件,然后把扩展名改为
.ipynb即可。
- 在同一个目录下,建立一个
data文件夹,把上面2个数据下载后保存在其中。
- 本课程的数据,默认都放置在工作目录下的
data文件夹中。
- 出现
FileNotFoundError, 99% 是代码没找到数据。
本章知识点安排
阶段 1:数据读取与初步查看
给你一个 Excel 文件,怎么读进来,读进来之后先看什么?看前几行、后几行、行列数、列名、数据类型、描述统计。先搞清楚表里有什么。
阶段 2:行列选择与条件筛选
表太大,怎么切出你要的那部分?选单列、选多列、按位置切、按条件筛选、复合条件、query()。
阶段 3:变量生成与数据修改
怎么从已有数据算出新东西?列运算、pd.cut() 分箱、np.where() 条件赋值、排序、排名。
阶段 4:常见数据问题处理
真实数据不会干干净净,缺失值、重复行、数字列里混了文本、日期不识别 … 怎么收拾? isna()、dropna()、fillna()、drop_duplicates()、pd.to_numeric()、pd.to_datetime()。
阶段 5:表的追加与合并
信息分散在两张表里,怎么拼到一起?同结构追加用 concat(),按共同列匹配用 merge()。
阶段 6:分组汇总与组内比较
如何按分组处理?比如,如何按班级算平均分? groupby() + agg() 往上聚合,transform() 往下映射。
阶段 7:数据重塑与结果表构造
同一份数据,行的排法、列的摆法不同,能回答的问题就不同。什么时候用长表,什么时候用宽表,怎么在两者之间切换? pivot_table()、set_index() / reset_index()。
阶段 8:时间序列专题
排序、shift()、diff()、pct_change()、cumprod()。
开始前:DataFrame 和 Series
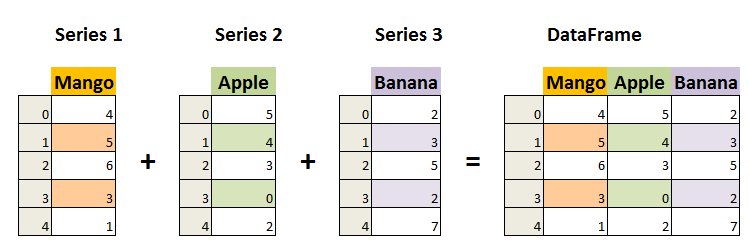
Pandas 主要处理二维表格。一个 DataFrame 可以理解为一张 Excel 表:有行、列、列名和行索引。一个 Series 可以理解为一列数据,它由索引和值组成。多个 Series 横向放在一起,就形成一个 DataFrame。
index + ndarray -> Series
index + Series + Series + ... -> DataFrame
Excel 和 CSV
常见表格数据主要有两类:
- Excel 文件:扩展名通常是
.xlsx。可以保存格式、颜色、多个工作表等信息,适合给人查看和编辑。
- CSV 文件:扩展名是
.csv。本质上是纯文本,只保存数据本身,不保存格式。它体积小、通用性强,几乎所有数据软件都能读取。
在数据分析中,Excel 和 CSV 都常见。需要给人直接打开查看时,Excel 更方便。如果不确定,CSV 往往更通用;
阶段 1:数据读取与初步查看
拿到一张表,第一步不是马上计算,而是先读进来,看它长什么样、有多少行列、每列是什么类型、主要数值大概在什么范围。只有先确认数据结构,后面的筛选、修改和统计才有基础。
最低要求:
- 能用
pd.read_excel() 读入 Excel 表。
- 能用
head() / tail() 看开头和末尾。
- 能用
shape、columns、dtypes、info() 判断表的结构和类型。
- 能用
describe() 看数值列的大致分布。
读取数据,并看表的样子
pd.read_excel("文件路径"):读取 Excel 文件,得到一张 DataFrame。
head() / tail():分别查看开头和末尾,默认显示 5 行;head(10) / tail(10) 可以指定行数。
import pandas as pd # 表格数据处理
import numpy as np # 数值和缺失值处理
pd.set_option("display.max_columns", 30) # 最多显示 30 列
pd.set_option("display.float_format", "{:.2f}".format) # 小数显示为 2 位
annual_raw = pd.read_excel("data/company_annual_operations_clean.xlsx") # 读取 Excel
annual_raw.head() # 查看前 5 行
| 0 |
2 |
万科A |
2018-12-31 |
2019-03-26 |
房地产业 |
广东省 |
深圳市 |
1991-01-29 |
正常上市 |
15285.79 |
12929.59 |
2976.79 |
1861.04 |
78.68 |
492.72 |
336.18 |
0.85 |
0.37 |
104300 |
| 1 |
2 |
万科A |
2019-12-31 |
2020-03-18 |
房地产业 |
广东省 |
深圳市 |
1991-01-29 |
正常上市 |
17299.29 |
14593.50 |
3678.94 |
2345.50 |
90.44 |
551.32 |
456.87 |
0.84 |
0.36 |
131505 |
| 2 |
2 |
万科A |
2020-12-31 |
2021-03-31 |
房地产业 |
广东省 |
深圳市 |
1991-01-29 |
正常上市 |
18691.77 |
15193.33 |
4191.12 |
2965.41 |
106.37 |
592.98 |
531.88 |
0.81 |
0.29 |
140565 |
| 3 |
4 |
国农科技 |
2018-12-31 |
2019-04-26 |
医药制造业 |
广东省 |
深圳市 |
1991-01-14 |
正常上市 |
3.51 |
1.68 |
3.67 |
0.66 |
2.71 |
-0.22 |
-0.53 |
0.48 |
0.82 |
210 |
| 4 |
4 |
国农科技 |
2019-12-31 |
2020-04-28 |
软件和信息技术服务业 |
广东省 |
深圳市 |
1991-01-14 |
正常上市 |
14.94 |
0.90 |
1.08 |
0.29 |
0.83 |
-0.04 |
-0.16 |
0.06 |
0.73 |
251 |
annual_raw.tail() # 查看后 5 行
| 64 |
638 |
万方发展 |
2019-12-31 |
2020-06-29 |
软件和信息技术服务业 |
吉林省 |
白山市 |
1996-11-26 |
正常上市 |
5.28 |
3.03 |
1.16 |
0.62 |
0.11 |
0.16 |
0.04 |
0.57 |
0.46 |
466 |
| 65 |
638 |
万方发展 |
2020-12-31 |
2021-04-14 |
软件和信息技术服务业 |
吉林省 |
白山市 |
1996-11-26 |
正常上市 |
5.07 |
3.39 |
1.11 |
0.80 |
0.13 |
-0.20 |
-0.02 |
0.67 |
0.28 |
670 |
| 66 |
682 |
东方电子 |
2018-12-31 |
2019-04-02 |
电气机械及器材制造业 |
山东省 |
烟台市 |
1997-01-21 |
正常上市 |
51.55 |
18.73 |
30.42 |
20.58 |
3.58 |
2.23 |
2.66 |
0.36 |
0.32 |
4564 |
| 67 |
682 |
东方电子 |
2019-12-31 |
2020-04-15 |
软件和信息技术服务业 |
山东省 |
烟台市 |
1997-01-21 |
正常上市 |
62.61 |
27.04 |
34.19 |
22.27 |
4.30 |
2.83 |
5.09 |
0.43 |
0.35 |
5087 |
| 68 |
682 |
东方电子 |
2020-12-31 |
2021-04-23 |
软件和信息技术服务业 |
山东省 |
烟台市 |
1997-01-21 |
正常上市 |
68.98 |
30.97 |
37.19 |
24.40 |
4.52 |
3.17 |
3.20 |
0.45 |
0.34 |
5665 |
查看表的结构和数值概况
shape:查看行数和列数。
columns.tolist():查看列名,并转换成普通列表,显示起来更直接。
dtypes / info():查看数据类型;info() 还会显示每列的非缺失值数量。常见类型包括:object 通常是文本或混合内容,int64 是整数,float64 是小数,datetime64[ns] 是日期时间,bool 是 True / False。
describe():查看数值列的样本数、均值、标准差、最小值、四分位数和最大值。先直接看结果;学完选列以后,可以再只选择真正适合统计的经营数值列。
annual_raw.shape # 查看行数和列数
annual_raw.columns.tolist() # 查看列名列表
['证券代码',
'股票简称',
'统计截止日期',
'年报公布日期',
'行业名称',
'所属省份',
'所属城市',
'首次上市日期',
'上市状态',
'总资产_亿元',
'总负债_亿元',
'营业收入_亿元',
'营业成本_亿元',
'销售费用_亿元',
'净利润_亿元',
'经营现金流_亿元',
'资产负债率',
'营业毛利率',
'员工数目']
annual_raw.dtypes # 查看每列数据类型
# object 文本或混合内容,int64 整数,float64 小数,datetime64[ns] 日期时间,bool 是 True / False
证券代码 int64
股票简称 object
统计截止日期 datetime64[ns]
年报公布日期 datetime64[ns]
行业名称 object
所属省份 object
所属城市 object
首次上市日期 datetime64[ns]
上市状态 object
总资产_亿元 float64
总负债_亿元 float64
营业收入_亿元 float64
营业成本_亿元 float64
销售费用_亿元 float64
净利润_亿元 float64
经营现金流_亿元 float64
资产负债率 float64
营业毛利率 float64
员工数目 int64
dtype: object
annual_raw.info() # 查看表结构摘要
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 69 entries, 0 to 68
Data columns (total 19 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 证券代码 69 non-null int64
1 股票简称 69 non-null object
2 统计截止日期 69 non-null datetime64[ns]
3 年报公布日期 69 non-null datetime64[ns]
4 行业名称 69 non-null object
5 所属省份 69 non-null object
6 所属城市 69 non-null object
7 首次上市日期 69 non-null datetime64[ns]
8 上市状态 69 non-null object
9 总资产_亿元 69 non-null float64
10 总负债_亿元 69 non-null float64
11 营业收入_亿元 69 non-null float64
12 营业成本_亿元 69 non-null float64
13 销售费用_亿元 69 non-null float64
14 净利润_亿元 69 non-null float64
15 经营现金流_亿元 69 non-null float64
16 资产负债率 69 non-null float64
17 营业毛利率 69 non-null float64
18 员工数目 69 non-null int64
dtypes: datetime64[ns](3), float64(9), int64(2), object(5)
memory usage: 10.4+ KB
annual_raw.describe() # 查看数值列描述统计
| count |
69.00 |
69 |
69 |
69 |
69.00 |
69.00 |
69.00 |
69.00 |
69.00 |
69.00 |
69.00 |
69.00 |
69.00 |
69.00 |
| mean |
231.39 |
2019-12-31 08:00:00 |
2020-04-11 01:23:28.695652096 |
1995-12-13 12:31:18.260869504 |
1072.96 |
830.10 |
432.11 |
318.19 |
25.86 |
42.71 |
45.99 |
0.53 |
0.29 |
18871.78 |
| min |
2.00 |
2018-12-31 00:00:00 |
2019-03-14 00:00:00 |
1991-01-14 00:00:00 |
3.51 |
0.90 |
1.08 |
0.29 |
0.05 |
-4.45 |
-32.30 |
0.06 |
0.05 |
148.00 |
| 25% |
16.00 |
2018-12-31 00:00:00 |
2019-04-26 00:00:00 |
1992-04-28 00:00:00 |
36.36 |
11.73 |
21.58 |
13.87 |
0.52 |
0.61 |
0.04 |
0.43 |
0.14 |
1132.00 |
| 50% |
70.00 |
2019-12-31 00:00:00 |
2020-04-17 00:00:00 |
1994-04-08 00:00:00 |
109.50 |
59.09 |
57.06 |
38.41 |
2.56 |
3.82 |
2.66 |
0.55 |
0.22 |
5504.00 |
| 75% |
423.00 |
2020-12-31 00:00:00 |
2021-03-27 00:00:00 |
1997-01-21 00:00:00 |
168.06 |
91.53 |
172.49 |
158.35 |
8.59 |
8.03 |
11.24 |
0.67 |
0.39 |
13432.00 |
| max |
682.00 |
2020-12-31 00:00:00 |
2021-04-30 00:00:00 |
2013-09-18 00:00:00 |
18691.77 |
15193.33 |
4191.12 |
2965.41 |
346.11 |
592.98 |
531.88 |
0.85 |
0.82 |
149239.00 |
| std |
241.80 |
NaN |
NaN |
NaN |
3536.24 |
2932.35 |
943.09 |
662.07 |
67.57 |
121.33 |
117.44 |
0.18 |
0.19 |
35995.12 |
建立工作副本
拿到原始数据后,建议复制一张工作副本。后面的筛选、删除、修改都在副本上做;如果处理过程中改错了,还可以回到原始表重新开始。
drop(columns=[...]):删除指定列。很多 pandas 操作会返回一张新表,原表通常不会自动改变。
.copy():复制出工作副本。这里先暂时放下 证券代码,集中观察公司经营变量。
annual = annual_raw.drop(columns=["证券代码"]).copy() # 删除暂不用的列并复制副本
annual.head() # 查看工作副本
| 0 |
万科A |
2018-12-31 |
2019-03-26 |
房地产业 |
广东省 |
深圳市 |
1991-01-29 |
正常上市 |
15285.79 |
12929.59 |
2976.79 |
1861.04 |
78.68 |
492.72 |
336.18 |
0.85 |
0.37 |
104300 |
| 1 |
万科A |
2019-12-31 |
2020-03-18 |
房地产业 |
广东省 |
深圳市 |
1991-01-29 |
正常上市 |
17299.29 |
14593.50 |
3678.94 |
2345.50 |
90.44 |
551.32 |
456.87 |
0.84 |
0.36 |
131505 |
| 2 |
万科A |
2020-12-31 |
2021-03-31 |
房地产业 |
广东省 |
深圳市 |
1991-01-29 |
正常上市 |
18691.77 |
15193.33 |
4191.12 |
2965.41 |
106.37 |
592.98 |
531.88 |
0.81 |
0.29 |
140565 |
| 3 |
国农科技 |
2018-12-31 |
2019-04-26 |
医药制造业 |
广东省 |
深圳市 |
1991-01-14 |
正常上市 |
3.51 |
1.68 |
3.67 |
0.66 |
2.71 |
-0.22 |
-0.53 |
0.48 |
0.82 |
210 |
| 4 |
国农科技 |
2019-12-31 |
2020-04-28 |
软件和信息技术服务业 |
广东省 |
深圳市 |
1991-01-14 |
正常上市 |
14.94 |
0.90 |
1.08 |
0.29 |
0.83 |
-0.04 |
-0.16 |
0.06 |
0.73 |
251 |
- 这里暂时去掉
证券代码,后面会更详细解释。
- 数据处理前,把数据拷贝一份再操作往往是好的做法:如果你把数据改坏了,从原始数据中再拷贝一份即可。
阶段 1 小结:拿到表格后,先用 head()、tail()、shape、columns、dtypes、info() 和 describe() 看结构、类型和大致分布。现在我们已经知道这张表的行列、变量和主要数值范围,下一步就可以从表里切出真正要看的部分。
练习:完成最后的阶段 1 练习。
阶段 2:行列选择与条件筛选
多数情况下,我们要处理的数据只是现有数据的一部分,所以需要先按分析要求把数据切出来。比如在这张公司年度经营表中,如果想观察 2020 年制造业中盈利、收入数据完整、负债率相对不高的公司,就要先筛选出这些公司,再只保留后面要比较的经营列。这里练的是一件事:从一张完整表里取出“现在需要”的行和列。
本节范例:选出 2020 年、行业名称包含“制造”、净利润为正、营业收入不缺失、资产负债率低于 0.7 的公司年度记录,作为下一步观察的名单。
最低要求:
- 能用列名取单列和多列。
- 能用
.loc 按标签选择行列。
- 能把条件生成的布尔序列放进
.loc 做筛选。
- 能用
&、|、~ 组合多个筛选条件。
DataFrame 和 Series 的结构
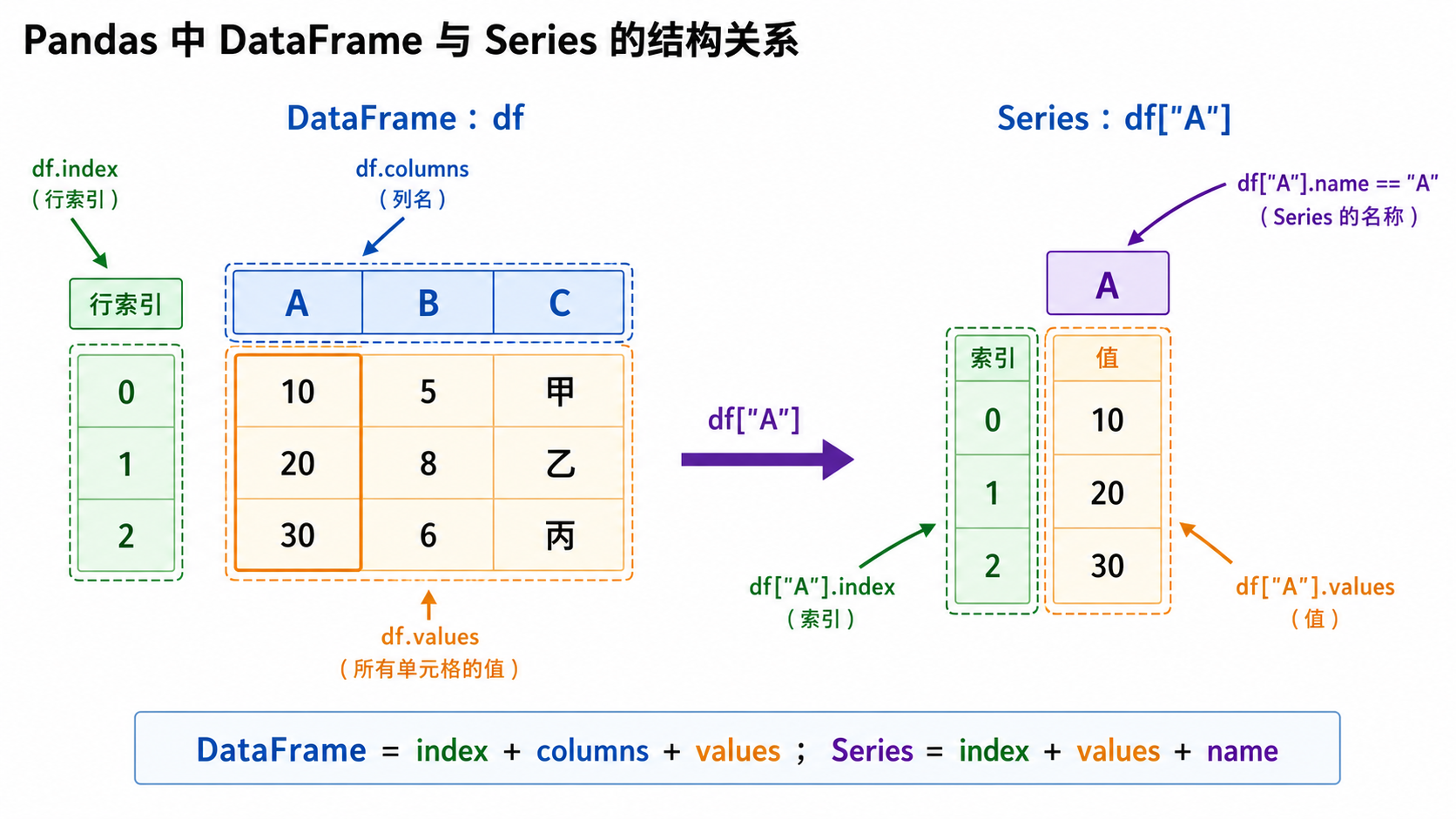
在 pandas 中,一张表可以拆成几个部分来看:
df.index:行索引,用来标识每一行。
df.columns:列名,用来标识每一列。
df.values:表格中的值。
df["A"]:从 DataFrame 中取出一列,会得到一个 Series。Series 也有自己的 index 和 values。
选择列
df["列名"]:用列名选择单列,返回 Series。Series 可以理解为一列数据。
df[[列名列表]]:用列名的 list 选择多列,返回 DataFrame。这里可以用上前面学过的 list 写法,例如 ["股票简称", "行业名称"]。
type():查看对象类型。这里用它区分 Series 和 DataFrame。
one_col = annual["营业收入_亿元"] # 用列名选择单列
one_col.head() # 查看单列数据
0 2976.79
1 3678.94
2 4191.12
3 3.67
4 1.08
Name: 营业收入_亿元, dtype: float64
pandas.core.series.Series
some_cols = annual[["股票简称", "行业名称", "营业收入_亿元"]] # 用列名 list 选择多列
some_cols.head() # 查看多列数据
| 0 |
万科A |
房地产业 |
2976.79 |
| 1 |
万科A |
房地产业 |
3678.94 |
| 2 |
万科A |
房地产业 |
4191.12 |
| 3 |
国农科技 |
医药制造业 |
3.67 |
| 4 |
国农科技 |
软件和信息技术服务业 |
1.08 |
type(some_cols) # 查看多列对象类型
pandas.core.frame.DataFrame
annual[["股票简称", "统计截止日期", "行业名称", "营业收入_亿元", "净利润_亿元"]].head() # 查看多列结果
| 0 |
万科A |
2018-12-31 |
房地产业 |
2976.79 |
492.72 |
| 1 |
万科A |
2019-12-31 |
房地产业 |
3678.94 |
551.32 |
| 2 |
万科A |
2020-12-31 |
房地产业 |
4191.12 |
592.98 |
| 3 |
国农科技 |
2018-12-31 |
医药制造业 |
3.67 |
-0.22 |
| 4 |
国农科技 |
2019-12-31 |
软件和信息技术服务业 |
1.08 |
-0.04 |
- 选择列的时候可以使用列名的 List,所以我们前面学的 List 的相关知识(比如列表推导式)都可以用上!
按标签选择:loc
.loc[行标签, 列标签]:按标签选择。行标签来自 index,列标签来自 columns。
指定一个标签,可以取出对应的行或列;指定一个标签列表,可以取出多行或多列。
标签区间写成 起点:终点。这里虽然也用了冒号,但它不是 Python 列表切片的规则,结束标签会被包含进来。
单独写 : 表示全选。它可以放在行位置,也可以放在列位置,例如 df.loc[:, ["列1", "列2"]] 表示保留所有行,只选几列。
annual.loc[0, "股票简称"] # 指定一个行标签和一个列标签
annual.loc[[0, 1, 2], ["股票简称", "统计截止日期", "行业名称"]] # 用标签列表选择多行多列
| 0 |
万科A |
2018-12-31 |
房地产业 |
| 1 |
万科A |
2019-12-31 |
房地产业 |
| 2 |
万科A |
2020-12-31 |
房地产业 |
loc的第一个参数其实是“行标签”,只是默认是序号(正如例子所示),但也可以是其他变量!后面会有更详细的例子。
annual.loc[0:3, "股票简称":"行业名称"] # 标签区间包含结束标签
| 0 |
万科A |
2018-12-31 |
2019-03-26 |
房地产业 |
| 1 |
万科A |
2019-12-31 |
2020-03-18 |
房地产业 |
| 2 |
万科A |
2020-12-31 |
2021-03-31 |
房地产业 |
| 3 |
国农科技 |
2018-12-31 |
2019-04-26 |
医药制造业 |
annual.loc[:, ["股票简称", "行业名称", "营业收入_亿元"]] # : 表示全选所有行,
# 和其实和 annual[["股票简称", "行业名称", "营业收入_亿元"]] 一样
| 0 |
万科A |
房地产业 |
2976.79 |
| 1 |
万科A |
房地产业 |
3678.94 |
| 2 |
万科A |
房地产业 |
4191.12 |
| 3 |
国农科技 |
医药制造业 |
3.67 |
| 4 |
国农科技 |
软件和信息技术服务业 |
1.08 |
| ... |
... |
... |
... |
| 64 |
万方发展 |
软件和信息技术服务业 |
1.16 |
| 65 |
万方发展 |
软件和信息技术服务业 |
1.11 |
| 66 |
东方电子 |
电气机械及器材制造业 |
30.42 |
| 67 |
东方电子 |
软件和信息技术服务业 |
34.19 |
| 68 |
东方电子 |
软件和信息技术服务业 |
37.19 |
69 rows × 3 columns
条件筛选
先看一个最基础的条件。条件筛选通常先得到一组 True / False,再把这组结果交给 .loc 取行。
df["列"] == 值:生成一组 True / False,这组结果就是一个 Series,可以作为 .loc 的行筛选条件。
df.loc[条件]:只把条件放进 .loc 时,pandas 会按行筛选,并保留所有列。
df.loc[条件, 列名列表]:在筛选行的同时,只保留需要看的列。
& / | / ~:分别表示“并且”“或者”“取反”。复合条件也会得到一组 True / False。每个条件外面都要加括号。
.notna():判断是否不是缺失值。筛选时常用来保留关键列有值的行。
.str.contains("关键词", na=False):判断文本列是否包含关键词;na=False 表示缺失值按“不包含”处理。
.dt.year:从日期列中取出年份。日期筛选中经常用到。
len():查看结果有多少行。筛选后通常要看一下行数和前后几行。
复合条件写起来长,但逻辑仍然是先得到一组布尔值,再把它交给 .loc。如果报错信息看不懂,先检查每个小条件是否都放在括号里。
# .loc 的行位置也可以接受一组 True / False。先把条件本身打出来看。
is_2020 = annual["统计截止日期"].dt.year == 2020 # 判断是否为 2020 年 注意:时间方法后面会继续介绍
is_2020.head(10) # 条件本身是一个 bool 序列
0 False
1 False
2 True
3 False
4 False
5 True
6 False
7 False
8 True
9 False
Name: 统计截止日期, dtype: bool
# 只把 bool 序列放进 .loc,默认筛选行,并保留所有列。
annual.loc[is_2020].head() # 查看 2020 年记录,保留全部变量
| 2 |
万科A |
2020-12-31 |
2021-03-31 |
房地产业 |
广东省 |
深圳市 |
1991-01-29 |
正常上市 |
18691.77 |
15193.33 |
4191.12 |
2965.41 |
106.37 |
592.98 |
531.88 |
0.81 |
0.29 |
140565 |
| 5 |
国华网安 |
2020-12-31 |
2021-04-28 |
软件和信息技术服务业 |
广东省 |
深圳市 |
1991-01-14 |
正常上市 |
15.64 |
1.07 |
2.81 |
0.69 |
0.51 |
0.62 |
0.04 |
0.07 |
0.75 |
264 |
| 8 |
深振业A |
2020-12-31 |
2021-03-31 |
房地产业 |
广东省 |
深圳市 |
1992-04-27 |
正常上市 |
154.35 |
75.97 |
29.35 |
15.67 |
0.45 |
9.03 |
-1.68 |
0.49 |
0.47 |
397 |
| 11 |
深物业A |
2020-12-31 |
2021-03-31 |
房地产业 |
广东省 |
深圳市 |
1992-03-30 |
正常上市 |
122.07 |
84.26 |
41.04 |
13.87 |
0.45 |
7.31 |
3.85 |
0.69 |
0.66 |
8035 |
| 14 |
沙河股份 |
2020-12-31 |
2021-03-27 |
房地产业 |
广东省 |
深圳市 |
1992-06-02 |
正常上市 |
24.34 |
14.80 |
3.47 |
2.15 |
0.13 |
0.09 |
2.59 |
0.61 |
0.38 |
153 |
在筛选的时候,loc[条件]或者loc[条件,列],其中的“条件”其实只是一个bool序列(一个Series),你的想法应该是:把条件(可能说多组条件)组合成一个bool序列,再放到条件里即可!
# 在条件后面再指定列列表,就能筛选行并只保留部分变量。
annual.loc[
is_2020, # 行位置:保留 2020 年记录
["股票简称", "行业名称", "营业收入_亿元", "净利润_亿元", "资产负债率"], # 列位置:保留指定列
].head() # 查看符合条件的关键列
| 2 |
万科A |
房地产业 |
4191.12 |
592.98 |
0.81 |
| 5 |
国华网安 |
软件和信息技术服务业 |
2.81 |
0.62 |
0.07 |
| 8 |
深振业A |
房地产业 |
29.35 |
9.03 |
0.49 |
| 11 |
深物业A |
房地产业 |
41.04 |
7.31 |
0.69 |
| 14 |
沙河股份 |
房地产业 |
3.47 |
0.09 |
0.61 |
# 筛选出 2020 年、制造业、盈利、收入不缺失且负债率较低的记录。
good_2020 = annual.loc[
(annual["统计截止日期"].dt.year == 2020) # 条件 1:2020 年
& (annual["行业名称"].str.contains("制造", na=False)) # 条件 2:行业名称包含“制造”
& (annual["净利润_亿元"] > 0) # 条件 3:净利润为正
& (annual["营业收入_亿元"].notna()) # 条件 4:营业收入不是缺失值
& (annual["资产负债率"] < 0.7), # 条件 5:资产负债率小于 0.7
["股票简称", "行业名称", "所属省份", "营业收入_亿元", "净利润_亿元", "资产负债率"], # 保留指定列
]
good_2020.head() # 查看筛选结果
| 20 |
深华发A |
计算机、通信和其他电子设备制造业 |
广东省 |
6.92 |
0.07 |
0.46 |
| 23 |
深科技 |
计算机、通信和其他电子设备制造业 |
广东省 |
149.67 |
9.53 |
0.63 |
| 26 |
富奥股份 |
汽车制造业 |
吉林省 |
111.13 |
9.08 |
0.43 |
| 29 |
深纺织A |
计算机、通信和其他电子设备制造业 |
广东省 |
21.09 |
0.43 |
0.22 |
| 32 |
德赛电池 |
电气机械及器材制造业 |
广东省 |
193.98 |
7.40 |
0.69 |
len(good_2020) # 查看筛选结果行数
good_2020.tail() # 查看筛选结果末尾
| 47 |
许继电气 |
电气机械及器材制造业 |
河南省 |
111.91 |
8.03 |
0.45 |
| 50 |
派林生物 |
医药制造业 |
山西省 |
10.50 |
1.83 |
0.41 |
| 53 |
东阿阿胶 |
医药制造业 |
山东省 |
34.09 |
0.41 |
0.11 |
| 56 |
江铃汽车 |
汽车制造业 |
江西省 |
330.96 |
5.51 |
0.61 |
| 62 |
万向钱潮 |
汽车制造业 |
浙江省 |
108.82 |
4.44 |
0.43 |
按位置选择:iloc
.iloc[行位置, 列位置]:按整数位置选择。行和列都使用从 0 开始的顺序位置。
.iloc 的区间规则和列表切片一致,起点:终点 不包含终点。例如 :5 表示位置 0 到 4。
: 同样表示全选,可以用于行位置或列位置。例如 df.iloc[:, :4] 表示所有行、前 4 列。
索引标签刚好是 0、1、2、3 时,.loc[0:3] 和 .iloc[:4] 看起来很像。它们的含义不同:.loc 看标签,.iloc 看位置。
annual.iloc[:5, :4] # 前 5 行、前 4 列,位置区间不包含终点
| 0 |
万科A |
2018-12-31 |
2019-03-26 |
房地产业 |
| 1 |
万科A |
2019-12-31 |
2020-03-18 |
房地产业 |
| 2 |
万科A |
2020-12-31 |
2021-03-31 |
房地产业 |
| 3 |
国农科技 |
2018-12-31 |
2019-04-26 |
医药制造业 |
| 4 |
国农科技 |
2019-12-31 |
2020-04-28 |
软件和信息技术服务业 |
用字符串写筛选条件
query("条件"):把筛选条件写成字符串,列名可以直接出现在字符串里。条件较短时,这种写法很方便。
and / or / not:在 query() 字符串里可以表示“并且”“或者”“取反”。
annual.query("净利润_亿元 > 0 and 资产负债率 < 0.7").head() # 用 query 筛选
| 5 |
国华网安 |
2020-12-31 |
2021-04-28 |
软件和信息技术服务业 |
广东省 |
深圳市 |
1991-01-14 |
正常上市 |
15.64 |
1.07 |
2.81 |
0.69 |
0.51 |
0.62 |
0.04 |
0.07 |
0.75 |
264 |
| 6 |
深振业A |
2018-12-31 |
2019-03-30 |
房地产业 |
广东省 |
深圳市 |
1992-04-27 |
正常上市 |
135.37 |
71.51 |
25.12 |
15.38 |
0.43 |
9.23 |
16.07 |
0.53 |
0.39 |
377 |
| 7 |
深振业A |
2019-12-31 |
2020-04-09 |
房地产业 |
广东省 |
深圳市 |
1992-04-27 |
正常上市 |
157.45 |
85.75 |
37.31 |
20.44 |
0.52 |
8.43 |
-1.94 |
0.54 |
0.45 |
385 |
| 8 |
深振业A |
2020-12-31 |
2021-03-31 |
房地产业 |
广东省 |
深圳市 |
1992-04-27 |
正常上市 |
154.35 |
75.97 |
29.35 |
15.67 |
0.45 |
9.03 |
-1.68 |
0.49 |
0.47 |
397 |
| 9 |
深物业A |
2018-12-31 |
2019-03-30 |
房地产业 |
广东省 |
深圳市 |
1992-03-30 |
正常上市 |
58.20 |
24.79 |
27.87 |
13.15 |
0.47 |
5.93 |
11.24 |
0.43 |
0.53 |
5504 |
- 多数情况下,
df[[列]] 、df.loc[行,列]或者 df.loc[行筛选条件,列] ,三者组合就能够完成大部分工作。
df.query() 在写复合条件的时候会比 loc 方便一点。
阶段 2 小结:想从表中取出一部分数据,可以按列名选列,用 iloc 按位置选,用 loc 按标签或条件选;条件较短时,query() 也很方便。筛选之后用 head()、tail() 和行数看一眼结果。good_2020 是一份观察名单,后面如果要继续分析,就可以围绕这样的名单生成更多变量。
练习:完成最后的阶段 2 练习。
阶段 3:变量生成与数据修改
选出需要的数据后,很多分析还要把原始字段转换成更接近问题的变量。比如收入、成本和利润可以说明经营规模和结果,但要比较盈利能力,还需要计算净利率;要观察上市时间,也可以从日期中提取年份并计算上市年限。新增变量后要重点看被改过的列,不需要每次都展示全部列。
范例:在原始公司年度经营数据基础上生成年份、净利率、人均营业收入、上市年限、资产规模、负债水平等新变量,并整理出 2020 年公司经营表现排名。
最低要求:
- 能用已有列计算并生成新列。
- 能从日期列提取年份等基本时间信息。
- 能用
.loc[条件, 列] = 值 做按条件赋值。
- 能用
sort_values() 和 rank() 做排序与排名。
用已有列生成新列
df["新列"] = 表达式:新增一列,写法和给字典增加新键类似。
列运算:表达式可以来自一列,也可以来自多列共同计算。例如净利率可以由净利润除以营业收入得到。
列运算完成后,先看几列核心输入和新列是否对得上。比如净利率应当和净利润、营业收入方向一致。
annual["净利率"] = annual["净利润_亿元"] / annual["营业收入_亿元"] # 用两列计算新列
annual[["股票简称", "营业收入_亿元", "净利润_亿元", "净利率"]].head() # 查看新列
| 0 |
万科A |
2976.79 |
492.72 |
0.17 |
| 1 |
万科A |
3678.94 |
551.32 |
0.15 |
| 2 |
万科A |
4191.12 |
592.98 |
0.14 |
| 3 |
国农科技 |
3.67 |
-0.22 |
-0.06 |
| 4 |
国农科技 |
1.08 |
-0.04 |
-0.04 |
从日期列生成变量
- 日期列可以用
.dt.year 取出年份,再继续计算。
# 从日期列生成年度变量。
annual["年份"] = annual["统计截止日期"].dt.year # 从日期提取年份
annual["上市年份"] = annual["首次上市日期"].dt.year # 从日期提取上市年份
annual["上市年限"] = annual["年份"] - annual["上市年份"] # 计算上市年限
annual[["股票简称", "统计截止日期", "年份", "首次上市日期", "上市年份", "上市年限"]].head() # 查看日期变量
| 0 |
万科A |
2018-12-31 |
2018 |
1991-01-29 |
1991 |
27 |
| 1 |
万科A |
2019-12-31 |
2019 |
1991-01-29 |
1991 |
28 |
| 2 |
万科A |
2020-12-31 |
2020 |
1991-01-29 |
1991 |
29 |
| 3 |
国农科技 |
2018-12-31 |
2018 |
1991-01-14 |
1991 |
27 |
| 4 |
国农科技 |
2019-12-31 |
2019 |
1991-01-14 |
1991 |
28 |
补充:时间方法简介
日期时间列可以通过 .dt 取出时间信息,常见用法包括:
.dt.year:年份,例如 2020。
.dt.month / .dt.day:月份和日期。
.dt.quarter:季度。
.dt.dayofweek:星期几,周一为 0,周日为 6。
.dt.strftime("格式"):把日期按指定格式转成文本,例如 %Y-%m 表示“年-月”。
生成布尔列和其他经营指标
比较运算:例如 df["净利润_亿元"] > 0 会得到一列 True / False,可以直接作为新列,也可以用来做筛选条件。
annual["是否盈利"] = annual["净利润_亿元"] > 0 # 比较结果生成布尔列
annual[["股票简称", "年份", "净利润_亿元", "是否盈利"]].head() # 查看布尔列
| 0 |
万科A |
2018 |
492.72 |
True |
| 1 |
万科A |
2019 |
551.32 |
True |
| 2 |
万科A |
2020 |
592.98 |
True |
| 3 |
国农科技 |
2018 |
-0.22 |
False |
| 4 |
国农科技 |
2019 |
-0.04 |
False |
annual["人均营业收入_万元"] = annual["营业收入_亿元"] * 10000 / annual["员工数目"] # 计算人均指标
annual[["股票简称", "年份", "营业收入_亿元", "员工数目", "人均营业收入_万元"]].head() # 查看人均指标
| 0 |
万科A |
2018 |
2976.79 |
104300 |
285.41 |
| 1 |
万科A |
2019 |
3678.94 |
131505 |
279.76 |
| 2 |
万科A |
2020 |
4191.12 |
140565 |
298.16 |
| 3 |
国农科技 |
2018 |
3.67 |
210 |
174.76 |
| 4 |
国农科技 |
2019 |
1.08 |
251 |
43.03 |
把连续变量分成几组
pd.cut():把连续数值分成几个区间,常用于生成“高、中、低”这类分组变量。
annual["资产规模"] = pd.cut(
annual["总资产_亿元"], # 要分箱的连续变量
bins=[0, 100, 1000, np.inf], # 分箱边界
labels=["小", "中", "大"], # 每个区间的标签
)
annual[["股票简称", "年份", "总资产_亿元", "资产规模"]].head() # 查看分箱结果
| 0 |
万科A |
2018 |
15285.79 |
大 |
| 1 |
万科A |
2019 |
17299.29 |
大 |
| 2 |
万科A |
2020 |
18691.77 |
大 |
| 3 |
国农科技 |
2018 |
3.51 |
小 |
| 4 |
国农科技 |
2019 |
14.94 |
小 |
按条件修改数据
np.where(条件, 条件成立时的值, 条件不成立时的值):适合二选一地生成新列。
.loc[条件, 列名] = 新值:适合对满足条件的行局部修改。
df[条件]["列"] = 新值:这类连续使用 [] 的写法称为链式赋值。pandas 不一定能判断你想修改原表还是临时结果,因此容易触发 warning;有时 warning 后原表并没有被修改。看到这类 warning 时,先把写法改成 .loc,再重新检查被修改的列。
df.loc[条件, "列"] = 新值:需要修改原表时,课堂和作业中建议使用这种写法。
# 根据资产负债率生成负债水平标签。
annual["负债水平"] = np.where(
annual["资产负债率"] >= 0.7, # 条件
"较高", # 条件成立时的值
"正常", # 条件不成立时的值
)
annual[["股票简称", "年份", "资产负债率", "负债水平"]].head() # 查看条件生成结果
| 0 |
万科A |
2018 |
0.85 |
较高 |
| 1 |
万科A |
2019 |
0.84 |
较高 |
| 2 |
万科A |
2020 |
0.81 |
较高 |
| 3 |
国农科技 |
2018 |
0.48 |
正常 |
| 4 |
国农科技 |
2019 |
0.06 |
正常 |
# 用 .loc 把高负债且亏损的记录标记为重点关注。
annual["重点关注"] = False # 先给整列一个默认值
annual.loc[
(annual["资产负债率"] >= 0.7) & (annual["净利润_亿元"] < 0), # 高负债且亏损
"重点关注",
] = True # 按条件局部修改,大致等于“条件筛选” + “赋值”
annual[["股票简称", "年份", "资产负债率", "净利润_亿元", "重点关注"]].head() # 查看局部修改结果
| 0 |
万科A |
2018 |
0.85 |
492.72 |
False |
| 1 |
万科A |
2019 |
0.84 |
551.32 |
False |
| 2 |
万科A |
2020 |
0.81 |
592.98 |
False |
| 3 |
国农科技 |
2018 |
0.48 |
-0.22 |
False |
| 4 |
国农科技 |
2019 |
0.06 |
-0.04 |
False |
np.where 会按条件生成一个新列,往往要赋值到原来的 df 中。.loc 是在原来的数据上进行修改,本质上是条件筛选 + 赋值。习惯做法是:建立一个列,填充默认值,然后用 .loc 修改符合条件的行。
排序和排名
排序最直觉的用途是“先看最大或最小的几条记录”。比如想知道 2020 年哪些公司营业收入最高,就先按 营业收入_亿元 排序,再看前几行。
sort_values("列名"):按一列排序。默认从小到大。
ascending=False:从大到小排序。
sort_values([列1, 列2], ascending=[...]):按多列排序。当前一列有重复值时,后一列会决定同一组内部的顺序。
rank():生成排名。默认从 1 开始,默认 ascending=True,也就是数值越小排名越靠前;如果希望数值越大排名越靠前,需要写 ascending=False。排序适合查看结果;如果需要把名次保存成一列继续使用,可以用 rank()。
.astype(int):把结果转换为整数类型。排名本身常常希望显示为整数。
# 先取出 2020 年样本,后面都围绕这一年排序。
annual_2020 = annual.loc[annual["年份"] == 2020].copy() # 筛选 2020 年并复制
annual_2020[["股票简称", "行业名称", "营业收入_亿元", "净利润_亿元"]].head() # 先看原始顺序
| 2 |
万科A |
房地产业 |
4191.12 |
592.98 |
| 5 |
国华网安 |
软件和信息技术服务业 |
2.81 |
0.62 |
| 8 |
深振业A |
房地产业 |
29.35 |
9.03 |
| 11 |
深物业A |
房地产业 |
41.04 |
7.31 |
| 14 |
沙河股份 |
房地产业 |
3.47 |
0.09 |
# 按营业收入从高到低排序,先看收入最高的公司。
revenue_sorted = annual_2020.sort_values("营业收入_亿元", ascending=False) # 收入降序
revenue_sorted[["股票简称", "行业名称", "营业收入_亿元", "净利润_亿元"]].head(10) # 查看收入最高的 10 家
| 2 |
万科A |
房地产业 |
4191.12 |
592.98 |
| 41 |
美的集团 |
电气机械及器材制造业 |
2842.21 |
275.07 |
| 44 |
潍柴动力 |
汽车制造业 |
1974.91 |
112.75 |
| 17 |
深康佳A |
计算机、通信和其他电子设备制造业 |
503.52 |
5.40 |
| 56 |
江铃汽车 |
汽车制造业 |
330.96 |
5.51 |
| 32 |
德赛电池 |
电气机械及器材制造业 |
193.98 |
7.40 |
| 23 |
深科技 |
计算机、通信和其他电子设备制造业 |
149.67 |
9.53 |
| 47 |
许继电气 |
电气机械及器材制造业 |
111.91 |
8.03 |
| 26 |
富奥股份 |
汽车制造业 |
111.13 |
9.08 |
| 62 |
万向钱潮 |
汽车制造业 |
108.82 |
4.44 |
revenue_sorted[["股票简称", "行业名称", "营业收入_亿元", "净利润_亿元"]].tail(5) # 再看收入较低的一端
| 50 |
派林生物 |
医药制造业 |
10.50 |
1.83 |
| 20 |
深华发A |
计算机、通信和其他电子设备制造业 |
6.92 |
0.07 |
| 14 |
沙河股份 |
房地产业 |
3.47 |
0.09 |
| 5 |
国华网安 |
软件和信息技术服务业 |
2.81 |
0.62 |
| 65 |
万方发展 |
软件和信息技术服务业 |
1.11 |
-0.20 |
# 多列排序常用于“先分组,再看组内顺序”:先按负债水平,再按营业收入。
annual_2020_rank = annual_2020.sort_values(
["负债水平", "营业收入_亿元"], # 先按离散标签,再按收入
ascending=[True, False], # 负债水平按文字顺序,收入从大到小
)
annual_2020_rank[[
"负债水平", "股票简称", "行业名称", "营业收入_亿元", "净利润_亿元", "净利率", "资产负债率"
]].head(12) # 查看同一负债水平内部的收入排序
| 41 |
正常 |
美的集团 |
电气机械及器材制造业 |
2842.21 |
275.07 |
0.10 |
0.66 |
| 56 |
正常 |
江铃汽车 |
汽车制造业 |
330.96 |
5.51 |
0.02 |
0.61 |
| 32 |
正常 |
德赛电池 |
电气机械及器材制造业 |
193.98 |
7.40 |
0.04 |
0.69 |
| 23 |
正常 |
深科技 |
计算机、通信和其他电子设备制造业 |
149.67 |
9.53 |
0.06 |
0.63 |
| 47 |
正常 |
许继电气 |
电气机械及器材制造业 |
111.91 |
8.03 |
0.07 |
0.45 |
| 26 |
正常 |
富奥股份 |
汽车制造业 |
111.13 |
9.08 |
0.08 |
0.43 |
| 62 |
正常 |
万向钱潮 |
汽车制造业 |
108.82 |
4.44 |
0.04 |
0.43 |
| 59 |
正常 |
神州信息 |
软件和信息技术服务业 |
106.86 |
4.66 |
0.04 |
0.53 |
| 11 |
正常 |
深物业A |
房地产业 |
41.04 |
7.31 |
0.18 |
0.69 |
| 68 |
正常 |
东方电子 |
软件和信息技术服务业 |
37.19 |
3.17 |
0.09 |
0.45 |
| 53 |
正常 |
东阿阿胶 |
医药制造业 |
34.09 |
0.41 |
0.01 |
0.11 |
| 38 |
正常 |
丰原药业 |
医药制造业 |
33.21 |
1.02 |
0.03 |
0.60 |
# rank() 默认从 1 开始排名;默认 ascending=True,数值越小排名越靠前。
annual_2020_rank["营业收入_亿元"].rank().head(10) # 查看默认排名结果
41 22.00
56 19.00
32 18.00
23 17.00
47 16.00
26 15.00
62 14.00
59 13.00
11 11.00
68 10.00
Name: 营业收入_亿元, dtype: float64
# 把营业收入排名保存成一列,便于后续继续使用。
annual_2020_rank["收入排名"] = (
annual_2020_rank["营业收入_亿元"]
.rank(ascending=False, method="min") # 按营业收入从大到小排名
.astype(int) # 转成整数
)
annual_2020_rank[["股票简称", "营业收入_亿元", "收入排名"]].head(10) # 查看排名列
| 41 |
美的集团 |
2842.21 |
2 |
| 56 |
江铃汽车 |
330.96 |
5 |
| 32 |
德赛电池 |
193.98 |
6 |
| 23 |
深科技 |
149.67 |
7 |
| 47 |
许继电气 |
111.91 |
8 |
| 26 |
富奥股份 |
111.13 |
9 |
| 62 |
万向钱潮 |
108.82 |
10 |
| 59 |
神州信息 |
106.86 |
11 |
| 11 |
深物业A |
41.04 |
13 |
| 68 |
东方电子 |
37.19 |
14 |
简单统计和展示列名
nunique():计算不重复取值数量。这里用于计算公司数量。
mean() / max():分别计算平均值和最大值。
describe():查看多列描述统计。
rename(columns={...}):重命名列。常用于把结果表整理成更适合展示的样子。
annual_2020 = annual[annual["年份"] == 2020] # 取出 2020 年样本
annual_2020["股票简称"].nunique() # 计算公司数量
annual_2020["营业收入_亿元"].mean() # 计算营业收入平均值
np.float64(473.61260869565217)
annual_2020["营业收入_亿元"].max() # 计算营业收入最大值
annual_2020[["营业收入_亿元", "净利润_亿元", "资产负债率", "净利率", "人均营业收入_万元"]].describe() # 查看多列描述统计
| count |
23.00 |
23.00 |
23.00 |
23.00 |
23.00 |
| mean |
473.61 |
46.05 |
0.53 |
0.07 |
179.67 |
| std |
1063.12 |
133.44 |
0.20 |
0.09 |
157.19 |
| min |
1.11 |
-0.20 |
0.07 |
-0.18 |
16.57 |
| 25% |
25.22 |
0.60 |
0.44 |
0.02 |
74.25 |
| 50% |
47.22 |
4.66 |
0.60 |
0.04 |
150.24 |
| 75% |
171.82 |
8.53 |
0.68 |
0.09 |
214.27 |
| max |
4191.12 |
592.98 |
0.81 |
0.31 |
739.29 |
rank_display = annual_2020_rank.rename(
columns={
"营业收入_亿元": "营业收入", # 改短列名
"净利润_亿元": "净利润", # 改短列名
}
)
rank_display[["股票简称", "行业名称", "营业收入", "净利润", "净利率"]].head() # 查看展示表
| 41 |
美的集团 |
电气机械及器材制造业 |
2842.21 |
275.07 |
0.10 |
| 56 |
江铃汽车 |
汽车制造业 |
330.96 |
5.51 |
0.02 |
| 32 |
德赛电池 |
电气机械及器材制造业 |
193.98 |
7.40 |
0.04 |
| 23 |
深科技 |
计算机、通信和其他电子设备制造业 |
149.67 |
9.53 |
0.06 |
| 47 |
许继电气 |
电气机械及器材制造业 |
111.91 |
8.03 |
0.07 |
阶段 3 小结:我们得到了 annual_2020_rank。这一阶段带出了列运算、新增列、日期列提取、布尔列、pd.cut()、按条件赋值、np.where()、排序、排名和简单统计。这张排名表先放在这里;接下来换到另一张指标表,处理它里面更接近真实数据的格式问题,等清洗完成后再和经营表合并。
练习:完成最后的阶段 3 练习。
阶段 4:常见数据问题处理
这一节按更直接的做法来:先原样读一次,找出问题;再读一次时指定能指定的类型。读入时解决不了的,再用一两行代码补。
最低要求:
- 能看出哪些列读错了类型。
- 能在
read_excel() 里用 converters、dtype、na_values 指定读取方式。
- 能修正证券代码、百分号这类读入后还需要处理的问题。
- 能去重复,并按需要删除缺失。
第一步:原样读一次,展示问题列
先不加任何参数,看看 pandas 会怎么读。这里不看全表,只看可能出问题的列。
indicators_raw = pd.read_excel("data/financial_indicators_dirty.xlsx")
problem_cols = [
"证券代码",
"股票简称",
"统计截止日期",
"加权平均净资产收益率",
"扣非净资产收益率",
"基本每股收益",
"非经常性损益_亿元",
"扣非净利润_亿元",
]
indicators_raw[problem_cols].head(10)
| 0 |
2 |
万科A |
2018-12-31 00:00:00 |
23.24 |
23.05 |
3.06 |
2.83 |
334.90 |
| 1 |
2 |
万科A |
2019-12-31 00:00:00 |
22.47 |
22.14 |
3.47 |
5.58 |
383.14 |
| 2 |
2 |
万科A |
2020/12/31 |
20.13 |
19.51 |
3.62 |
12.78 |
402.38 |
| 3 |
4 |
国农科技 |
2020-13-31 |
-17 |
-19.29 |
-0.24 |
0.03 |
-0.23 |
| 4 |
4 |
国农科技 |
2019-12-31 00:00:00 |
2.97 |
-24.12 |
0.04 |
-- |
-0.27 |
| 5 |
4 |
国华网安 |
2020-12-31 00:00:00 |
4.54 |
4.42 |
0.39 |
0.02 |
0.63 |
| 6 |
6 |
深振业A |
2018-12-31 00:00:00 |
14.86% |
14.80 |
0.65 |
0.04 |
8.71 |
| 7 |
6 |
深振业A |
2019-12-31 00:00:00 |
12.39 |
NaN |
0.59 |
0.22 |
7.79 |
| 8 |
6 |
深振业A |
2020-12-31 00:00:00 |
12.26 |
11.85 |
缺失 |
0.29 |
8.35 |
| 9 |
11 |
深物业A |
2018-12-31 00:00:00 |
18.94 |
18.89 |
0.99 |
0.01 |
5.91 |
indicators_raw[problem_cols].dtypes
证券代码 int64
股票简称 object
统计截止日期 object
加权平均净资产收益率 object
扣非净资产收益率 float64
基本每股收益 object
非经常性损益_亿元 object
扣非净利润_亿元 float64
dtype: object
这里能看到:证券代码被读成了数字,前面的 0 会丢;日期还不是日期类型;部分数值列因为有 %、--、缺失,没有全部读成数值。
第二步:指定类型,再读一次
读取时先处理能处理的部分:证券代码按 str 读;明确的特殊值用 na_values 读成缺失;能直接读成数值的列用 float。
加权平均净资产收益率 本来也应该是数值,但有一个值带 %。我们不判断它是格式错误还是录入错误,后面直接按数值转换,不能转换的值会变成缺失。
float_cols = [
"扣非净资产收益率",
"基本每股收益",
"非经常性损益_亿元",
"扣非净利润_亿元",
]
indicators = pd.read_excel(
"data/financial_indicators_dirty.xlsx",
converters={"证券代码": str},
dtype={col: float for col in float_cols},
na_values=["--", "缺失", ""],
)
indicators[problem_cols].head(10)
| 0 |
2 |
万科A |
2018-12-31 00:00:00 |
23.24 |
23.05 |
3.06 |
2.83 |
334.90 |
| 1 |
000002 |
万科A |
2019-12-31 00:00:00 |
22.47 |
22.14 |
3.47 |
5.58 |
383.14 |
| 2 |
000002 |
万科A |
2020/12/31 |
20.13 |
19.51 |
3.62 |
12.78 |
402.38 |
| 3 |
000004 |
国农科技 |
2020-13-31 |
-17 |
-19.29 |
-0.24 |
0.03 |
-0.23 |
| 4 |
000004 |
国农科技 |
2019-12-31 00:00:00 |
2.97 |
-24.12 |
0.04 |
NaN |
-0.27 |
| 5 |
000004 |
国华网安 |
2020-12-31 00:00:00 |
4.54 |
4.42 |
0.39 |
0.02 |
0.63 |
| 6 |
000006 |
深振业A |
2018-12-31 00:00:00 |
14.86% |
14.80 |
0.65 |
0.04 |
8.71 |
| 7 |
000006 |
深振业A |
2019-12-31 00:00:00 |
12.39 |
NaN |
0.59 |
0.22 |
7.79 |
| 8 |
000006 |
深振业A |
2020-12-31 00:00:00 |
12.26 |
11.85 |
NaN |
0.29 |
8.35 |
| 9 |
000011 |
深物业A |
2018-12-31 00:00:00 |
18.94 |
18.89 |
0.99 |
0.01 |
5.91 |
indicators[problem_cols].dtypes
证券代码 object
股票简称 object
统计截止日期 object
加权平均净资产收益率 object
扣非净资产收益率 float64
基本每股收益 float64
非经常性损益_亿元 float64
扣非净利润_亿元 float64
dtype: object
现在大多数数值列已经是 float。剩下要补的只有几件事:证券代码补 0,日期转成日期类型,异常写法的数值列转成数值。
第三步:补证券代码
先看最小代码:zfill(6) 会把字符串补齐到 6 位。
indicators["证券代码"] = indicators["证券代码"].str.strip().str.zfill(6)
indicators["股票简称"] = indicators["股票简称"].str.strip()
indicators[["证券代码", "股票简称"]].head(8)
| 0 |
000002 |
万科A |
| 1 |
000002 |
万科A |
| 2 |
000002 |
万科A |
| 3 |
000004 |
国农科技 |
| 4 |
000004 |
国农科技 |
| 5 |
000004 |
国华网安 |
| 6 |
000006 |
深振业A |
| 7 |
000006 |
深振业A |
第四步:补日期类型
日期列转成 datetime。无法识别的日期会变成缺失值。
indicators["统计截止日期"] = pd.to_datetime(indicators["统计截止日期"], errors="coerce")
indicators["年份"] = indicators["统计截止日期"].dt.year
indicators[["证券代码", "股票简称", "统计截止日期", "年份"]].head(10)
| 0 |
000002 |
万科A |
2018-12-31 |
2018.00 |
| 1 |
000002 |
万科A |
2019-12-31 |
2019.00 |
| 2 |
000002 |
万科A |
2020-12-31 |
2020.00 |
| 3 |
000004 |
国农科技 |
NaT |
NaN |
| 4 |
000004 |
国农科技 |
2019-12-31 |
2019.00 |
| 5 |
000004 |
国华网安 |
2020-12-31 |
2020.00 |
| 6 |
000006 |
深振业A |
2018-12-31 |
2018.00 |
| 7 |
000006 |
深振业A |
2019-12-31 |
2019.00 |
| 8 |
000006 |
深振业A |
2020-12-31 |
2020.00 |
| 9 |
000011 |
深物业A |
2018-12-31 |
2018.00 |
indicators.loc[
indicators["统计截止日期"].isna(),
["证券代码", "股票简称", "统计截止日期"],
]
第五步:处理异常写法的数值列
加权平均净资产收益率 应该是数值列。对这类列,不确定的异常写法不要替它解释,直接按数值转换;不能转换的值变成缺失。先看最小代码。
pd.to_numeric(pd.Series(["14.86%", "12.39"]), errors="coerce")
0 NaN
1 12.39
dtype: float64
pd.to_numeric(pd.Series(["23.24", "14.86%", "12.39"]), errors="coerce")
0 23.24
1 NaN
2 12.39
dtype: float64
indicators["加权平均净资产收益率"] = pd.to_numeric(
indicators["加权平均净资产收益率"],
errors="coerce",
)
indicators[["证券代码", "股票简称", "加权平均净资产收益率"]].head(10)
| 0 |
000002 |
万科A |
23.24 |
| 1 |
000002 |
万科A |
22.47 |
| 2 |
000002 |
万科A |
20.13 |
| 3 |
000004 |
国农科技 |
-17.00 |
| 4 |
000004 |
国农科技 |
2.97 |
| 5 |
000004 |
国华网安 |
4.54 |
| 6 |
000006 |
深振业A |
NaN |
| 7 |
000006 |
深振业A |
12.39 |
| 8 |
000006 |
深振业A |
12.26 |
| 9 |
000011 |
深物业A |
18.94 |
number_cols = [
"加权平均净资产收益率",
"扣非净资产收益率",
"基本每股收益",
"非经常性损益_亿元",
"扣非净利润_亿元",
]
indicators[number_cols].dtypes
加权平均净资产收益率 float64
扣非净资产收益率 float64
基本每股收益 float64
非经常性损益_亿元 float64
扣非净利润_亿元 float64
dtype: object
第六步:替换特殊值
有些访谈或问卷数据会在数值列里用特殊数字记录情况。例如“月收入”肯定不能为负,如果数据说明规定 -1 表示“不愿回答”,就应该把这一列里的 -1 转成缺失。
注意:这只适用于本来不可能为负的数值变量。代码和日期不这样处理;财务指标也不能简单处理,因为负数可能表示亏损。
income_demo = pd.Series([3200, -1, 5800, 4100])
income_demo.replace({-1: np.nan})
0 3200.00
1 NaN
2 5800.00
3 4100.00
dtype: float64
本表中的 加权平均净资产收益率、基本每股收益、扣非净利润_亿元 等财务指标都可能为负,所以这里不把 -1 当作缺失。当前只检查读取时已经产生的缺失。
indicators[["证券代码", "统计截止日期", *number_cols]].isna().sum()
证券代码 0
统计截止日期 1
加权平均净资产收益率 1
扣非净资产收益率 1
基本每股收益 1
非经常性损益_亿元 1
扣非净利润_亿元 0
dtype: int64
第七步:去重复
先看最小例子。公司年度数据通常按“公司 + 日期”判断重复,而不是要求整行完全相同。
duplicate_demo = pd.DataFrame({
"证券代码": ["000001", "000001", "000002"],
"统计截止日期": ["2020-12-31", "2020-12-31", "2020-12-31"],
"基本每股收益": [1.20, 1.30, 0.80],
})
duplicate_demo
| 0 |
000001 |
2020-12-31 |
1.20 |
| 1 |
000001 |
2020-12-31 |
1.30 |
| 2 |
000002 |
2020-12-31 |
0.80 |
duplicate_demo.drop_duplicates(subset=["证券代码", "统计截止日期"])
| 0 |
000001 |
2020-12-31 |
1.20 |
| 2 |
000002 |
2020-12-31 |
0.80 |
rows_before = len(indicators)
indicators_clean = indicators.drop_duplicates(subset=["证券代码", "统计截止日期"]).copy()
rows_after_duplicates = len(indicators_clean)
pd.DataFrame({
"步骤": ["去重复前", "去重复后"],
"行数": [rows_before, rows_after_duplicates],
})
第八步:dropna,得到干净表
dropna() 不能总是直接用。先看最小例子:默认 dropna() 会删除“任意一列有缺失”的行。
dropna_demo = pd.DataFrame({
"证券代码": ["000001", "000002", "000003"],
"统计截止日期": ["2020-12-31", "2020-12-31", "2020-12-31"],
"基本每股收益": [1.20, np.nan, 0.80],
"备注": ["正常", "未披露", np.nan],
})
dropna_demo
| 0 |
000001 |
2020-12-31 |
1.20 |
正常 |
| 1 |
000002 |
2020-12-31 |
NaN |
未披露 |
| 2 |
000003 |
2020-12-31 |
0.80 |
NaN |
dropna_demo.dropna() # 默认:任意列有缺失就删除
| 0 |
000001 |
2020-12-31 |
1.20 |
正常 |
这个默认结果有时太严格。例如 备注 缺失不一定影响财务分析,不一定要删掉整行。所以实际清洗时常用 subset= 指定要检查哪些列。
dropna_demo.dropna(subset=["证券代码", "统计截止日期", "基本每股收益"])
| 0 |
000001 |
2020-12-31 |
1.20 |
正常 |
| 2 |
000003 |
2020-12-31 |
0.80 |
NaN |
回到本表。后面要按 证券代码 和 统计截止日期 合并,并且要使用这些财务指标。这里的选择是:连接键或指标列有缺失就删除。
这不是所有任务都必须这样做。如果后面只分析部分指标,可以只把那些指标放进 subset;如果缺失本身有研究意义,也可以先保留。
indicators_clean = indicators_clean.dropna(
subset=["证券代码", "统计截止日期", *number_cols]
).copy()
len(indicators_clean)
indicators_clean["扣非盈利"] = indicators_clean["扣非净利润_亿元"] > 0
indicators_clean[[
"证券代码", "股票简称", "统计截止日期", "基本每股收益", "扣非净利润_亿元", "扣非盈利"
]].head()
| 0 |
000002 |
万科A |
2018-12-31 |
3.06 |
334.90 |
True |
| 1 |
000002 |
万科A |
2019-12-31 |
3.47 |
383.14 |
True |
| 2 |
000002 |
万科A |
2020-12-31 |
3.62 |
402.38 |
True |
| 5 |
000004 |
国华网安 |
2020-12-31 |
0.39 |
0.63 |
True |
| 9 |
000011 |
深物业A |
2018-12-31 |
0.99 |
5.91 |
True |
indicators_clean.isna().sum()
证券代码 0
股票简称 0
统计截止日期 0
加权平均净资产收益率 0
扣非净资产收益率 0
基本每股收益 0
非经常性损益_亿元 0
扣非净利润_亿元 0
年份 0
扣非盈利 0
dtype: int64
阶段 4 小结:先原样读一次,发现问题;再用 read_excel() 的参数把能指定的类型指定好。读入后只补少数问题:证券代码补 0、日期转类型、异常数值按数值转换。不能转换的值作为缺失,最后去重复并按需要 dropna,得到 indicators_clean。
练习:完成最后的阶段 4 练习。
阶段 5:表的追加与合并
这一阶段只看两件事:concat() 和 merge()。
concat() 负责把表拼起来。同结构的表可以上下追加;不同列或不同索引的表也可以拼,但 pandas 会按列名或索引自动对齐。
merge() 负责按连接键合并信息。比如经营表里有营业收入,指标表里有每股收益,只要两张表都有证券代码,就可以把这些信息合到同一行。
最低要求:
- 能用
pd.concat() 把同结构表上下追加。
- 能理解
concat() 会按列名或 index 对齐。
- 能用
merge(on=...) 按连接键合并两张表。
- 能区分
left、inner、outer 三种常用连接方式。
准备几张小表
先用几张手工小表演示。小表的好处是行数少,能一眼看出命令本身做了什么。
sales_2019 = pd.DataFrame({
"证券代码": ["000001", "000002"],
"证券简称": ["平安银行", "万科A"],
"年份": [2019, 2019],
"营业收入_亿元": [1379.58, 3678.94],
})
sales_2019 # 第一张小表
| 0 |
000001 |
平安银行 |
2019 |
1379.58 |
| 1 |
000002 |
万科A |
2019 |
3678.94 |
sales_2020 = pd.DataFrame({
"证券代码": ["000001", "000002"],
"证券简称": ["平安银行", "万科A"],
"年份": [2020, 2020],
"营业收入_亿元": [1535.42, 4191.12],
})
sales_2020 # 第二张小表
| 0 |
000001 |
平安银行 |
2020 |
1535.42 |
| 1 |
000002 |
万科A |
2020 |
4191.12 |
concat:上下追加
pd.concat([表1, 表2, ...]):默认上下追加,也就是增加行。
ignore_index=True:追加后重新生成连续索引。教学和作业中通常这样写,结果更干净。
pd.concat([sales_2019, sales_2020], ignore_index=True) # 上下追加两张同结构表
| 0 |
000001 |
平安银行 |
2019 |
1379.58 |
| 1 |
000002 |
万科A |
2019 |
3678.94 |
| 2 |
000001 |
平安银行 |
2020 |
1535.42 |
| 3 |
000002 |
万科A |
2020 |
4191.12 |
concat:按列名对齐
上下追加时,pandas 按列名对齐,不是按第几列对齐。如果某张表多了一列,其他表这一列的位置会显示缺失值。
sales_2020_more = sales_2020.copy() # 复制一张 2020 年小表
sales_2020_more["净利润_亿元"] = [289.28, 592.98] # 多出一列净利润
pd.concat([sales_2019, sales_2020_more], ignore_index=True) # 按列名对齐,缺少的列显示为缺失值
| 0 |
000001 |
平安银行 |
2019 |
1379.58 |
NaN |
| 1 |
000002 |
万科A |
2019 |
3678.94 |
NaN |
| 2 |
000001 |
平安银行 |
2020 |
1535.42 |
289.28 |
| 3 |
000002 |
万科A |
2020 |
4191.12 |
592.98 |
concat:横向拼接时按 index 对齐
axis=1 表示横向拼接,也就是增加列。横向拼接时,pandas 按 index 对齐。index 对不上的地方会显示缺失值。
company_name = pd.DataFrame(
{"证券简称": ["平安银行", "万科A", "国农科技"]},
index=["000001", "000002", "000004"],
)
company_revenue = pd.DataFrame(
{"营业收入_亿元": [1535.42, 4191.12]},
index=["000001", "000002"],
)
pd.concat([company_name, company_revenue], axis=1) # 横向拼接,按 index 对齐
| 000001 |
平安银行 |
1535.42 |
| 000002 |
万科A |
4191.12 |
| 000004 |
国农科技 |
NaN |
merge:按连接键合并
merge():按共同字段合并两张表。
on="列名":指定连接键。连接键就是两张表中用来匹配记录的列。
先用两张小表看最简单的合并。左表有 3 家公司的收入,右表有其中 2 家公司的每股收益,另外多出 1 家左表没有的公司。
merge_left_demo = pd.DataFrame({
"证券代码": ["000001", "000002", "000004"],
"证券简称": ["平安银行", "万科A", "国农科技"],
"营业收入_亿元": [1535.42, 4191.12, 1.71],
})
merge_left_demo # 左表:公司收入
| 0 |
000001 |
平安银行 |
1535.42 |
| 1 |
000002 |
万科A |
4191.12 |
| 2 |
000004 |
国农科技 |
1.71 |
merge_right_demo = pd.DataFrame({
"证券代码": ["000001", "000002", "000011"],
"基本每股收益": [1.40, 3.62, 1.34],
})
merge_right_demo # 右表:每股收益
| 0 |
000001 |
1.40 |
| 1 |
000002 |
3.62 |
| 2 |
000011 |
1.34 |
merge_left_demo.merge(merge_right_demo, on="证券代码") # 默认 inner,只保留两边都有的公司
| 0 |
000001 |
平安银行 |
1535.42 |
1.40 |
| 1 |
000002 |
万科A |
4191.12 |
3.62 |
merge:how 决定保留哪些行
how="left":保留左表全部行,右表没有匹配上的地方显示缺失值。
how="inner":只保留两张表都能匹配上的行。默认就是 inner。
how="outer":两张表里的行都保留,匹配不上的位置显示缺失值。
merge_left_demo.merge(merge_right_demo, on="证券代码", how="left") # 保留左表全部公司
| 0 |
000001 |
平安银行 |
1535.42 |
1.40 |
| 1 |
000002 |
万科A |
4191.12 |
3.62 |
| 2 |
000004 |
国农科技 |
1.71 |
NaN |
merge_left_demo.merge(merge_right_demo, on="证券代码", how="inner") # 只保留两边都有的公司
| 0 |
000001 |
平安银行 |
1535.42 |
1.40 |
| 1 |
000002 |
万科A |
4191.12 |
3.62 |
merge_left_demo.merge(merge_right_demo, on="证券代码", how="outer") # 两边公司都保留
| 0 |
000001 |
平安银行 |
1535.42 |
1.40 |
| 1 |
000002 |
万科A |
4191.12 |
3.62 |
| 2 |
000004 |
国农科技 |
1.71 |
NaN |
| 3 |
000011 |
NaN |
NaN |
1.34 |
- 还有其他写法
pd.merge(df1,df2, 其他参数) 也是一样的
- 如果你什么参数都不写,merge会自己找2个表同名的列,但一般推荐明确指定
on=,避免意外
merge可以串联,比如 df1.merge(df2).merge(df3),但不推荐,一般merge一次最少要看一下merge的结果。
合并本章后续要用的表
小表示例看清楚后,再回到本章的数据。这里把公司年度经营表和清洗后的财务指标表按“证券代码 + 统计截止日期”合并,得到后续阶段要用的 analysis_df。
# 读取带证券代码的经营表,只做必要的代码格式处理。
annual_for_merge = pd.read_excel(
"data/company_annual_operations_clean.xlsx",
converters={"证券代码": lambda x: str(x).strip().zfill(6)}, # 证券代码按字符串读取
).rename(columns={"股票简称": "证券简称"})
annual_for_merge[["证券代码", "证券简称", "统计截止日期", "营业收入_亿元", "净利润_亿元"]].head() # 查看经营表
| 0 |
000002 |
万科A |
2018-12-31 |
2976.79 |
492.72 |
| 1 |
000002 |
万科A |
2019-12-31 |
3678.94 |
551.32 |
| 2 |
000002 |
万科A |
2020-12-31 |
4191.12 |
592.98 |
| 3 |
000004 |
国农科技 |
2018-12-31 |
3.67 |
-0.22 |
| 4 |
000004 |
国农科技 |
2019-12-31 |
1.08 |
-0.04 |
indicator_cols = ["证券代码", "统计截止日期", "基本每股收益", "扣非净利润_亿元", "扣非盈利"]
analysis_df = annual_for_merge.merge(
indicators_clean[indicator_cols],
on=["证券代码", "统计截止日期"], # 按公司和日期匹配
how="left", # 保留经营表所有行
)
analysis_df[["证券代码", "证券简称", "统计截止日期", "营业收入_亿元", "基本每股收益"]].head() # 查看合并结果
| 0 |
000002 |
万科A |
2018-12-31 |
2976.79 |
3.06 |
| 1 |
000002 |
万科A |
2019-12-31 |
3678.94 |
3.47 |
| 2 |
000002 |
万科A |
2020-12-31 |
4191.12 |
3.62 |
| 3 |
000004 |
国农科技 |
2018-12-31 |
3.67 |
NaN |
| 4 |
000004 |
国农科技 |
2019-12-31 |
1.08 |
NaN |
阶段 5 小结:concat() 用来拼表,重点看是上下拼还是左右拼,以及按列名还是按 index 对齐;merge() 用来按连接键合并表,重点看 on 和 how。我们得到了后续分析要用的 analysis_df。
练习:完成最后的阶段 5 练习。
阶段 6:分组汇总与组内比较
分组汇总的核心很简单:先把数据按某一列分成若干组,再在每个组里面做同一个统计。不要一开始就把筛选、排序、多个指标和新变量都放在一起。
这一阶段按下面的顺序来:
- 不分组,先统计 1 列。
- 按 1 个变量分组,还是只统计 1 列。
- 统计 1 列的多个指标。
- 统计多列。
- 最后再用命名聚合、
transform() 和组内排序。
最低要求:
- 能用
groupby() 按一列或多列分组。
- 能用
mean()、sum()、agg() 计算每组统计量。
- 能用
reset_index() 把分组结果整理回普通表。
- 能用
transform() 把组内统计值带回明细表。
先准备最少的分析变量
后面只需要 年份 和 净利率。先生成这两个变量,再取出 2020 年明细表。
analysis_df = analysis_df.copy()
analysis_df["年份"] = analysis_df["统计截止日期"].dt.year
analysis_df["净利率"] = analysis_df["净利润_亿元"] / analysis_df["营业收入_亿元"]
analysis_df[["证券代码", "证券简称", "年份", "行业名称", "营业收入_亿元", "净利润_亿元", "净利率"]].head()
| 0 |
000002 |
万科A |
2018 |
房地产业 |
2976.79 |
492.72 |
0.17 |
| 1 |
000002 |
万科A |
2019 |
房地产业 |
3678.94 |
551.32 |
0.15 |
| 2 |
000002 |
万科A |
2020 |
房地产业 |
4191.12 |
592.98 |
0.14 |
| 3 |
000004 |
国农科技 |
2018 |
医药制造业 |
3.67 |
-0.22 |
-0.06 |
| 4 |
000004 |
国农科技 |
2019 |
软件和信息技术服务业 |
1.08 |
-0.04 |
-0.04 |
analysis_2020 = analysis_df.loc[analysis_df["年份"] == 2020].copy()
analysis_2020[["证券代码", "证券简称", "行业名称", "营业收入_亿元", "净利润_亿元", "净利率"]].head()
| 2 |
000002 |
万科A |
房地产业 |
4191.12 |
592.98 |
0.14 |
| 5 |
000004 |
国华网安 |
软件和信息技术服务业 |
2.81 |
0.62 |
0.22 |
| 8 |
000006 |
深振业A |
房地产业 |
29.35 |
9.03 |
0.31 |
| 11 |
000011 |
深物业A |
房地产业 |
41.04 |
7.31 |
0.18 |
| 14 |
000014 |
沙河股份 |
房地产业 |
3.47 |
0.09 |
0.03 |
第一步:不分组,统计 1 列
先看全体 2020 年公司的平均营业收入。这里没有分组,结果只有一个数。
analysis_2020["营业收入_亿元"].mean()
np.float64(473.61260869565217)
第二步:按 1 个变量分组,统计 1 列
加上 groupby("行业名称") 后,还是求营业收入均值,但现在是在每个行业内部分别求均值。
industry_mean_revenue_2020 = analysis_2020.groupby("行业名称")["营业收入_亿元"].mean()
industry_mean_revenue_2020.head()
行业名称
医药制造业 25.93
房地产业 1066.24
汽车制造业 631.46
电气机械及器材制造业 798.83
计算机、通信和其他电子设备制造业 170.30
Name: 营业收入_亿元, dtype: float64
这一步得到的是以行业名称作为索引的结果。需要继续筛选、排序、保存时,常把索引还原成普通列。
industry_mean_revenue_2020.reset_index().head()
| 0 |
医药制造业 |
25.93 |
| 1 |
房地产业 |
1066.24 |
| 2 |
汽车制造业 |
631.46 |
| 3 |
电气机械及器材制造业 |
798.83 |
| 4 |
计算机、通信和其他电子设备制造业 |
170.30 |
industry_mean_revenue_2020.sort_values(ascending=False).head() # 排序只是为了先看较大的行业
行业名称
房地产业 1066.24
电气机械及器材制造业 798.83
汽车制造业 631.46
计算机、通信和其他电子设备制造业 170.30
软件和信息技术服务业 36.99
Name: 营业收入_亿元, dtype: float64
第三步:统计 1 列的多个指标
如果只关心营业收入这一列,可以对它同时计算均值、合计和最大值。
analysis_2020.groupby("行业名称")["营业收入_亿元"].agg(["mean", "sum", "max"]).head()
| 行业名称 |
|
|
|
| 医药制造业 |
25.93 |
77.80 |
34.09 |
| 房地产业 |
1066.24 |
4264.98 |
4191.12 |
| 汽车制造业 |
631.46 |
2525.82 |
1974.91 |
| 电气机械及器材制造业 |
798.83 |
3195.32 |
2842.21 |
| 计算机、通信和其他电子设备制造业 |
170.30 |
681.20 |
503.52 |
第四步:统计多列
如果要同时看营业收入和净利润,可以先选多列,再对这些列使用同一个统计方法。
analysis_2020.groupby("行业名称")[["营业收入_亿元", "净利润_亿元"]].mean().head()
| 行业名称 |
|
|
| 医药制造业 |
25.93 |
1.09 |
| 房地产业 |
1066.24 |
152.35 |
| 汽车制造业 |
631.46 |
32.95 |
| 电气机械及器材制造业 |
798.83 |
72.77 |
| 计算机、通信和其他电子设备制造业 |
170.30 |
3.86 |
第五步:命名聚合
前面的写法适合入门。真实结果表通常需要清楚的列名,例如 公司数、平均营业收入_亿元。这时使用命名聚合。
industry_2020 = analysis_2020.groupby("行业名称").agg(
公司数=("证券简称", "nunique"),
平均营业收入_亿元=("营业收入_亿元", "mean"),
营业收入合计_亿元=("营业收入_亿元", "sum"),
平均净利率=("净利率", "mean"),
平均资产负债率=("资产负债率", "mean"),
)
industry_2020.head()
| 行业名称 |
|
|
|
|
|
| 医药制造业 |
3 |
25.93 |
77.80 |
0.07 |
0.37 |
| 房地产业 |
4 |
1066.24 |
4264.98 |
0.16 |
0.65 |
| 汽车制造业 |
4 |
631.46 |
2525.82 |
0.05 |
0.54 |
| 电气机械及器材制造业 |
4 |
798.83 |
3195.32 |
0.05 |
0.63 |
| 计算机、通信和其他电子设备制造业 |
4 |
170.30 |
681.20 |
0.03 |
0.52 |
industry_2020 = industry_2020.sort_values("营业收入合计_亿元", ascending=False)
industry_2020.head()
| 行业名称 |
|
|
|
|
|
| 房地产业 |
4 |
1066.24 |
4264.98 |
0.16 |
0.65 |
| 电气机械及器材制造业 |
4 |
798.83 |
3195.32 |
0.05 |
0.63 |
| 汽车制造业 |
4 |
631.46 |
2525.82 |
0.05 |
0.54 |
| 计算机、通信和其他电子设备制造业 |
4 |
170.30 |
681.20 |
0.03 |
0.52 |
| 软件和信息技术服务业 |
4 |
36.99 |
147.97 |
0.04 |
0.43 |
分组汇总后要看公司数。只有一两家公司的行业,均值和最大值可能更像个案,不一定代表行业整体。
按多个变量分组
一个分组列会得到“行业”层面的结果。两个分组列会得到“行业-年份”层面的结果。
industry_year_mean = analysis_df.groupby(["行业名称", "年份"])["净利率"].mean()
industry_year_mean.head(12)
行业名称 年份
医药制造业 2018 0.08
2019 0.02
2020 0.07
房地产业 2018 0.29
2019 0.16
2020 0.16
汽车制造业 2018 0.06
2019 0.05
2020 0.05
电气机械及器材制造业 2018 0.05
2019 0.07
2020 0.05
Name: 净利率, dtype: float64
industry_year = analysis_df.groupby(["行业名称", "年份"]).agg(
公司数=("证券简称", "nunique"),
平均营业收入_亿元=("营业收入_亿元", "mean"),
平均净利率=("净利率", "mean"),
).reset_index()
industry_year.head(12)
| 0 |
医药制造业 |
2018 |
4 |
28.95 |
0.08 |
| 1 |
医药制造业 |
2019 |
3 |
23.71 |
0.02 |
| 2 |
医药制造业 |
2020 |
3 |
25.93 |
0.07 |
| 3 |
房地产业 |
2018 |
4 |
758.34 |
0.29 |
| 4 |
房地产业 |
2019 |
4 |
940.06 |
0.16 |
| 5 |
房地产业 |
2020 |
4 |
1066.24 |
0.16 |
| 6 |
汽车制造业 |
2018 |
4 |
516.80 |
0.06 |
| 7 |
汽车制造业 |
2019 |
4 |
560.45 |
0.05 |
| 8 |
汽车制造业 |
2020 |
4 |
631.46 |
0.05 |
| 9 |
电气机械及器材制造业 |
2018 |
5 |
587.76 |
0.05 |
| 10 |
电气机械及器材制造业 |
2019 |
4 |
777.86 |
0.07 |
| 11 |
电气机械及器材制造业 |
2020 |
4 |
798.83 |
0.05 |
自定义聚合函数
常见统计量可以直接写字符串,例如 "mean"、"sum"。如果要算一个自己定义的指标,可以先写函数,再放进 agg()。
def value_range(x):
return x.max() - x.min()
value_range(analysis_2020["营业收入_亿元"])
industry_gap_2020 = analysis_2020.groupby("行业名称").agg(
收入均值=("营业收入_亿元", "mean"),
收入差距=("营业收入_亿元", value_range),
)
industry_gap_2020.sort_values("收入差距", ascending=False).head()
| 行业名称 |
|
|
| 房地产业 |
1066.24 |
4187.65 |
| 电气机械及器材制造业 |
798.83 |
2794.99 |
| 汽车制造业 |
631.46 |
1866.09 |
| 计算机、通信和其他电子设备制造业 |
170.30 |
496.60 |
| 软件和信息技术服务业 |
36.99 |
105.75 |
把组内统计值放回明细表
agg() 的结果是每组一行。transform() 的结果和原表一样长,所以可以放回明细表,继续做公司和行业平均水平的比较。
industry_mean_for_each_row = analysis_2020.groupby("行业名称")["营业收入_亿元"].transform("mean")
industry_mean_for_each_row.head()
2 1066.24
5 36.99
8 1066.24
11 1066.24
14 1066.24
Name: 营业收入_亿元, dtype: float64
industry_compare_2020 = analysis_2020.copy()
industry_compare_2020["行业平均收入_亿元"] = industry_mean_for_each_row
industry_compare_2020["高于行业平均"] = (
industry_compare_2020["营业收入_亿元"] > industry_compare_2020["行业平均收入_亿元"]
)
industry_compare_2020[[
"行业名称", "证券简称", "营业收入_亿元", "行业平均收入_亿元", "高于行业平均"
]].head(10)
| 2 |
房地产业 |
万科A |
4191.12 |
1066.24 |
True |
| 5 |
软件和信息技术服务业 |
国华网安 |
2.81 |
36.99 |
False |
| 8 |
房地产业 |
深振业A |
29.35 |
1066.24 |
False |
| 11 |
房地产业 |
深物业A |
41.04 |
1066.24 |
False |
| 14 |
房地产业 |
沙河股份 |
3.47 |
1066.24 |
False |
| 17 |
计算机、通信和其他电子设备制造业 |
深康佳A |
503.52 |
170.30 |
True |
| 20 |
计算机、通信和其他电子设备制造业 |
深华发A |
6.92 |
170.30 |
False |
| 23 |
计算机、通信和其他电子设备制造业 |
深科技 |
149.67 |
170.30 |
False |
| 26 |
汽车制造业 |
富奥股份 |
111.13 |
631.46 |
False |
| 29 |
计算机、通信和其他电子设备制造业 |
深纺织A |
21.09 |
170.30 |
False |
每组取前几名
每组取前几名通常分两步:先把表排好序,再分组取 head(n)。先单独看排序结果,再做分组,比较容易检查。
sorted_2020 = analysis_2020.sort_values(
["行业名称", "营业收入_亿元"],
ascending=[True, False],
)
sorted_2020[["行业名称", "证券代码", "证券简称", "营业收入_亿元"]].head(10)
| 53 |
医药制造业 |
000423 |
东阿阿胶 |
34.09 |
| 38 |
医药制造业 |
000153 |
丰原药业 |
33.21 |
| 50 |
医药制造业 |
000403 |
派林生物 |
10.50 |
| 2 |
房地产业 |
000002 |
万科A |
4191.12 |
| 11 |
房地产业 |
000011 |
深物业A |
41.04 |
| 8 |
房地产业 |
000006 |
深振业A |
29.35 |
| 14 |
房地产业 |
000014 |
沙河股份 |
3.47 |
| 44 |
汽车制造业 |
000338 |
潍柴动力 |
1974.91 |
| 56 |
汽车制造业 |
000550 |
江铃汽车 |
330.96 |
| 26 |
汽车制造业 |
000030 |
富奥股份 |
111.13 |
top2_by_industry = sorted_2020.groupby("行业名称").head(2)
top2_by_industry[["行业名称", "证券代码", "证券简称", "营业收入_亿元", "净利率"]].head(14)
| 53 |
医药制造业 |
000423 |
东阿阿胶 |
34.09 |
0.01 |
| 38 |
医药制造业 |
000153 |
丰原药业 |
33.21 |
0.03 |
| 2 |
房地产业 |
000002 |
万科A |
4191.12 |
0.14 |
| 11 |
房地产业 |
000011 |
深物业A |
41.04 |
0.18 |
| 44 |
汽车制造业 |
000338 |
潍柴动力 |
1974.91 |
0.06 |
| 56 |
汽车制造业 |
000550 |
江铃汽车 |
330.96 |
0.02 |
| 41 |
电气机械及器材制造业 |
000333 |
美的集团 |
2842.21 |
0.10 |
| 32 |
电气机械及器材制造业 |
000049 |
德赛电池 |
193.98 |
0.04 |
| 17 |
计算机、通信和其他电子设备制造业 |
000016 |
深康佳A |
503.52 |
0.01 |
| 23 |
计算机、通信和其他电子设备制造业 |
000021 |
深科技 |
149.67 |
0.06 |
| 59 |
软件和信息技术服务业 |
000555 |
神州信息 |
106.86 |
0.04 |
| 68 |
软件和信息技术服务业 |
000682 |
东方电子 |
37.19 |
0.09 |
分组循环
多数汇总可以用 agg() 或 transform()。如果组内逻辑比较复杂,也可以用循环逐组处理。下面仍然只做一件事:每个行业取收入最高的 1 家公司。
top_list = []
for industry, group in analysis_2020.groupby("行业名称"):
top_company = group.sort_values("营业收入_亿元", ascending=False).head(1)
top_list.append(top_company)
industry_top_company = pd.concat(top_list, ignore_index=True)
industry_top_company = industry_top_company[["行业名称", "证券代码", "证券简称", "营业收入_亿元", "净利率"]]
industry_top_company = industry_top_company.sort_values("营业收入_亿元", ascending=False)
industry_top_company.head()
| 1 |
房地产业 |
000002 |
万科A |
4191.12 |
0.14 |
| 3 |
电气机械及器材制造业 |
000333 |
美的集团 |
2842.21 |
0.10 |
| 2 |
汽车制造业 |
000338 |
潍柴动力 |
1974.91 |
0.06 |
| 4 |
计算机、通信和其他电子设备制造业 |
000016 |
深康佳A |
503.52 |
0.01 |
| 5 |
软件和信息技术服务业 |
000555 |
神州信息 |
106.86 |
0.04 |
阶段 6 小结:分组汇总先从最小版本理解。先统计 1 列,再加入 groupby();先统计一个指标,再扩展到多个指标和多列;需要展示结果时再排序;需要回到明细表时用 transform()。
练习:完成最后的阶段 6 练习。
阶段 7:数据重塑与结果表构造
明细表适合记录原始观测,但不一定适合直接回答问题。比如,如果想比较每家公司 2018 年到 2020 年的营业收入变化,把年份展开成列会更直观;如果要把结果发给别人,也需要整理成一张结构清楚的结果表。阶段 6 得到的是行业层面的汇总,阶段 7 回到公司层面,构造一张便于展示和保存的结果表。
范例:把公司年度营业收入从长表整理成宽表,每家公司一行,2018、2019、2020 年收入分别成为列;再计算 2018-2020 年收入增长率,并整理成可以保存的公司结果表。
最低要求:
- 能用
pivot_table() 把长表整理成宽表。
- 能在宽表上继续做列运算。
- 能用
set_index() / reset_index() 在索引和普通列之间切换。
- 能把结果表整理成普通表,并展示关键列。
长表和宽表
长表:同一个变量的不同年份放在多行里。当前 analysis_df 就是长表,一家公司一年一行。
宽表:同一个变量的不同年份展开成多列。比较跨年变化时,宽表更方便。
pivot_table(index=..., columns=..., values=...):把长表整理成宽表。index 决定一行代表什么,columns 决定哪一列的取值展开成新列,values 决定单元格里放什么数值。
analysis_df[["证券代码", "证券简称", "行业名称", "年份", "营业收入_亿元", "资产负债率"]].head(9) # 查看长表
| 0 |
000002 |
万科A |
房地产业 |
2018 |
2976.79 |
0.85 |
| 1 |
000002 |
万科A |
房地产业 |
2019 |
3678.94 |
0.84 |
| 2 |
000002 |
万科A |
房地产业 |
2020 |
4191.12 |
0.81 |
| 3 |
000004 |
国农科技 |
医药制造业 |
2018 |
3.67 |
0.48 |
| 4 |
000004 |
国农科技 |
软件和信息技术服务业 |
2019 |
1.08 |
0.06 |
| 5 |
000004 |
国华网安 |
软件和信息技术服务业 |
2020 |
2.81 |
0.07 |
| 6 |
000006 |
深振业A |
房地产业 |
2018 |
25.12 |
0.53 |
| 7 |
000006 |
深振业A |
房地产业 |
2019 |
37.31 |
0.54 |
| 8 |
000006 |
深振业A |
房地产业 |
2020 |
29.35 |
0.49 |
revenue_wide_simple = analysis_df.pivot_table(
index="证券简称", # 每家公司一行
columns="年份", # 年份展开成列
values="营业收入_亿元", # 单元格里放营业收入
)
revenue_wide_simple.head() # 查看最简单的收入宽表
| 证券简称 |
|
|
|
| 万向钱潮 |
113.62 |
105.81 |
108.82 |
| 万方发展 |
1.19 |
1.16 |
1.11 |
| 万科A |
2976.79 |
3678.94 |
4191.12 |
| 东方电子 |
30.42 |
34.19 |
37.19 |
| 东阿阿胶 |
73.38 |
29.59 |
34.09 |
保留更多公司信息
index 可以放一个列名,也可以放列名列表。用列名列表时,结果的行索引会包含多个层级。
aggfunc 决定同一个位置有多条记录时怎样合并。pivot_table() 默认使用均值,当前每家公司每年只有一条记录,用 aggfunc="first" 表示直接取这条记录。
revenue_wide = analysis_df.pivot_table(
index=["证券代码", "证券简称", "行业名称"], # 用多列标识公司
columns="年份", # 年份展开成列
values="营业收入_亿元", # 单元格里放营业收入
aggfunc="first", # 每家公司每年只有一条记录,直接取第一条
)
revenue_wide.head() # 查看带公司信息的收入宽表
| 证券代码 |
证券简称 |
行业名称 |
|
|
|
| 000002 |
万科A |
房地产业 |
2976.79 |
3678.94 |
4191.12 |
| 000004 |
国农科技 |
医药制造业 |
3.67 |
NaN |
NaN |
| 软件和信息技术服务业 |
NaN |
1.08 |
NaN |
| 国华网安 |
软件和信息技术服务业 |
NaN |
NaN |
2.81 |
| 000006 |
深振业A |
房地产业 |
25.12 |
37.31 |
29.35 |
在宽表上继续计算
宽表生成后,不同年份已经是不同列,可以直接做列运算。
reset_index():把索引还原成普通列。结果表通常更适合把公司代码、简称、行业作为普通列展示。
宽表上的列运算很直观,但也要看分母是否缺失或为 0。增长率异常大时,先回到原始收入列看原因。
revenue_wide["收入增长率_2018_2020"] = revenue_wide[2020] / revenue_wide[2018] - 1 # 跨年增长率
revenue_wide[[2018, 2019, 2020, "收入增长率_2018_2020"]].head() # 查看新增列
| 证券代码 |
证券简称 |
行业名称 |
|
|
|
|
| 000002 |
万科A |
房地产业 |
2976.79 |
3678.94 |
4191.12 |
0.41 |
| 000004 |
国农科技 |
医药制造业 |
3.67 |
NaN |
NaN |
NaN |
| 软件和信息技术服务业 |
NaN |
1.08 |
NaN |
NaN |
| 国华网安 |
软件和信息技术服务业 |
NaN |
NaN |
2.81 |
NaN |
| 000006 |
深振业A |
房地产业 |
25.12 |
37.31 |
29.35 |
0.17 |
company_summary = (
revenue_wide
.reset_index() # 公司代码、简称、行业回到普通列
.sort_values("收入增长率_2018_2020", ascending=False) # 按增长率降序
)
company_summary[["证券代码", "证券简称", "行业名称", 2018, 2020, "收入增长率_2018_2020"]].head(10) # 查看结果表
| 11 |
000045 |
深纺织A |
计算机、通信和其他电子设备制造业 |
12.72 |
21.09 |
0.66 |
| 5 |
000011 |
深物业A |
房地产业 |
27.87 |
41.04 |
0.47 |
| 10 |
000030 |
富奥股份 |
汽车制造业 |
78.53 |
111.13 |
0.42 |
| 0 |
000002 |
万科A |
房地产业 |
2976.79 |
4191.12 |
0.41 |
| 17 |
000400 |
许继电气 |
电气机械及器材制造业 |
82.17 |
111.91 |
0.36 |
| 16 |
000338 |
潍柴动力 |
汽车制造业 |
1592.56 |
1974.91 |
0.24 |
| 23 |
000555 |
神州信息 |
软件和信息技术服务业 |
90.77 |
106.86 |
0.18 |
| 22 |
000550 |
江铃汽车 |
汽车制造业 |
282.49 |
330.96 |
0.17 |
| 4 |
000006 |
深振业A |
房地产业 |
25.12 |
29.35 |
0.17 |
| 12 |
000049 |
德赛电池 |
电气机械及器材制造业 |
172.49 |
193.98 |
0.12 |
索引和普通列之间切换
set_index("列名"):把普通列设为索引。需要按某个标识查找行时很方便。
reset_index():把索引还原成普通列。保存或继续合并前经常会这样做。
indexed = company_summary.set_index("证券代码") # 把证券代码设为索引
indexed[["证券简称", "行业名称", 2018, 2020, "收入增长率_2018_2020"]].head() # 查看索引表
| 证券代码 |
|
|
|
|
|
| 000045 |
深纺织A |
计算机、通信和其他电子设备制造业 |
12.72 |
21.09 |
0.66 |
| 000011 |
深物业A |
房地产业 |
27.87 |
41.04 |
0.47 |
| 000030 |
富奥股份 |
汽车制造业 |
78.53 |
111.13 |
0.42 |
| 000002 |
万科A |
房地产业 |
2976.79 |
4191.12 |
0.41 |
| 000400 |
许继电气 |
电气机械及器材制造业 |
82.17 |
111.91 |
0.36 |
indexed.reset_index()[["证券代码", "证券简称", "行业名称", 2018, 2020, "收入增长率_2018_2020"]].head() # 索引还原成普通列
| 0 |
000045 |
深纺织A |
计算机、通信和其他电子设备制造业 |
12.72 |
21.09 |
0.66 |
| 1 |
000011 |
深物业A |
房地产业 |
27.87 |
41.04 |
0.47 |
| 2 |
000030 |
富奥股份 |
汽车制造业 |
78.53 |
111.13 |
0.42 |
| 3 |
000002 |
万科A |
房地产业 |
2976.79 |
4191.12 |
0.41 |
| 4 |
000400 |
许继电气 |
电气机械及器材制造业 |
82.17 |
111.91 |
0.36 |
构造小表
pd.Series():构造一列带索引的数据。
pd.DataFrame({...}):用字典构造表。字典的键会成为列名,值会成为列数据。
构造小表常用于临时整理规则、演示结果或手工输入少量信息。
s = pd.Series([10, 20, 30], index=["A", "B", "C"], name="得分") # 构造 Series
s # 查看 Series
A 10
B 20
C 30
Name: 得分, dtype: int64
demo_df = pd.DataFrame({
"公司": ["甲", "乙", "丙"],
"收入": [100, 120, 80],
}) # 构造 DataFrame
demo_df # 查看小表
保存结果
to_excel("路径", index=False):保存为 Excel。适合给人直接打开查看。
to_csv("路径", index=False):保存为 CSV。格式简单,通用性强。
index=False:不把索引写入文件。普通结果表通常使用这个参数。
company_summary[["证券代码", "证券简称", "行业名称", 2018, 2020, "收入增长率_2018_2020"]].head() # 查看保存对象
| 11 |
000045 |
深纺织A |
计算机、通信和其他电子设备制造业 |
12.72 |
21.09 |
0.66 |
| 5 |
000011 |
深物业A |
房地产业 |
27.87 |
41.04 |
0.47 |
| 10 |
000030 |
富奥股份 |
汽车制造业 |
78.53 |
111.13 |
0.42 |
| 0 |
000002 |
万科A |
房地产业 |
2976.79 |
4191.12 |
0.41 |
| 17 |
000400 |
许继电气 |
电气机械及器材制造业 |
82.17 |
111.91 |
0.36 |
# 保存几个阶段成果。
analysis_df[analysis_df["年份"] == 2020].to_excel("data/finance_2020_rank_full.xlsx", index=False) # 保存 2020 年明细
industry_2020.to_excel("data/industry_2020_full_summary.xlsx") # 保存行业汇总
company_summary.to_excel("data/company_full_summary.xlsx", index=False) # 保存公司结果表
company_summary.to_csv("data/company_full_summary.csv", index=False) # 保存 CSV 版本
print("已保存阶段成果")
pd.read_csv("data/company_full_summary.csv").head() # 读回 CSV 检查
| 0 |
45 |
深纺织A |
计算机、通信和其他电子设备制造业 |
12.72 |
21.58 |
21.09 |
0.66 |
| 1 |
11 |
深物业A |
房地产业 |
27.87 |
39.62 |
41.04 |
0.47 |
| 2 |
30 |
富奥股份 |
汽车制造业 |
78.53 |
100.64 |
111.13 |
0.42 |
| 3 |
2 |
万科A |
房地产业 |
2976.79 |
3678.94 |
4191.12 |
0.41 |
| 4 |
400 |
许继电气 |
电气机械及器材制造业 |
82.17 |
101.56 |
111.91 |
0.36 |
阶段 7 小结:这一阶段先从最简单的 pivot_table() 看长表变宽表,再扩展到多列索引、宽表列运算、set_index()、reset_index()、构造 Series / DataFrame,以及保存 Excel 和 CSV。结果表保存前先看几行,保存后再读回来看一眼,这能发现路径、索引和列名问题。
练习:完成最后的阶段 7 练习。
阶段 8:时间序列专题
本章的公司经营表已经是一张年度面板:同一家公司在不同年份有多行记录。处理这类数据时,关键是先确认时间顺序,再在公司内部计算上一年、本年变化和增长率。阶段 7 把年份展开成了列;阶段 8 保持长表形态,用时间顺序直接计算变化。
范例:先选出万科 A 的年度经营记录,确认上一年收入、收入增加额和收入增长率怎么算;再把同样的计算扩展到所有公司,找出 2020 年收入增长率较高的公司。
最低要求:
- 能先按公司和日期排序。
- 能用
shift()、diff()、pct_change() 计算上一期、差分和增长率。
- 能在
groupby() 之后做公司内部的时间计算。
- 能先检查单家公司结果,再推广到全部公司。
先确认时间顺序
sort_values():按公司和日期排序。时间序列计算通常要先排序。
同一家公司跨年比较时,先单独取出一家公司看清楚,确认结果符合直觉,再推广到全部公司。
时间计算最怕顺序错。shift() 不会自动理解“上一年”,它只是取当前顺序里的上一行;所以排序是计算前的必要步骤。
panel_ts = analysis_df.sort_values(["证券代码", "统计截止日期"]).copy() # 按公司和时间排序
panel_ts[["证券代码", "证券简称", "统计截止日期", "年份", "营业收入_亿元", "净利润_亿元"]].head(9) # 查看排序后的面板
| 0 |
000002 |
万科A |
2018-12-31 |
2018 |
2976.79 |
492.72 |
| 1 |
000002 |
万科A |
2019-12-31 |
2019 |
3678.94 |
551.32 |
| 2 |
000002 |
万科A |
2020-12-31 |
2020 |
4191.12 |
592.98 |
| 3 |
000004 |
国农科技 |
2018-12-31 |
2018 |
3.67 |
-0.22 |
| 4 |
000004 |
国农科技 |
2019-12-31 |
2019 |
1.08 |
-0.04 |
| 5 |
000004 |
国华网安 |
2020-12-31 |
2020 |
2.81 |
0.62 |
| 6 |
000006 |
深振业A |
2018-12-31 |
2018 |
25.12 |
9.23 |
| 7 |
000006 |
深振业A |
2019-12-31 |
2019 |
37.31 |
8.43 |
| 8 |
000006 |
深振业A |
2020-12-31 |
2020 |
29.35 |
9.03 |
company_ts = panel_ts.loc[panel_ts["证券简称"] == "万科A"].copy() # 筛选万科A
company_ts[["证券代码", "证券简称", "统计截止日期", "年份", "营业收入_亿元", "净利润_亿元"]] # 查看公司年度记录
| 0 |
000002 |
万科A |
2018-12-31 |
2018 |
2976.79 |
492.72 |
| 1 |
000002 |
万科A |
2019-12-31 |
2019 |
3678.94 |
551.32 |
| 2 |
000002 |
万科A |
2020-12-31 |
2020 |
4191.12 |
592.98 |
上一期数值:shift()
shift(1):把数据向后移动一期。当前行看到的就是上一行的值。
在排好序的单家公司数据里,上一行就是上一年。第一年没有上一年,所以结果是缺失值。
company_ts["上一年营业收入_亿元"] = company_ts["营业收入_亿元"].shift(1) # 上一年收入
company_ts[["证券简称", "年份", "营业收入_亿元", "上一年营业收入_亿元"]] # 查看上一年收入
| 0 |
万科A |
2018 |
2976.79 |
NaN |
| 1 |
万科A |
2019 |
3678.94 |
2976.79 |
| 2 |
万科A |
2020 |
4191.12 |
3678.94 |
本期和上一期的差:diff()
diff():当前值减去上一期值。对收入来说,就是本年比上一年增加了多少。
company_ts["收入增加额_亿元"] = company_ts["营业收入_亿元"].diff() # 本年收入减上一年收入
company_ts[["证券简称", "年份", "营业收入_亿元", "上一年营业收入_亿元", "收入增加额_亿元"]] # 查看收入增加额
| 0 |
万科A |
2018 |
2976.79 |
NaN |
NaN |
| 1 |
万科A |
2019 |
3678.94 |
2976.79 |
702.15 |
| 2 |
万科A |
2020 |
4191.12 |
3678.94 |
512.18 |
本期相对上一期的变化率:pct_change()
pct_change():计算当前值相对上一期值的增长率。
增长率要和原始数值一起看。基数很小时,一个不大的增加额也可能对应很高的增长率。
company_ts["收入增长率"] = company_ts["营业收入_亿元"].pct_change() # 收入增长率
company_ts[["证券简称", "年份", "营业收入_亿元", "收入增加额_亿元", "收入增长率"]] # 查看收入增长率
| 0 |
万科A |
2018 |
2976.79 |
NaN |
NaN |
| 1 |
万科A |
2019 |
3678.94 |
702.15 |
0.24 |
| 2 |
万科A |
2020 |
4191.12 |
512.18 |
0.14 |
用增长率构造累计指数
(1 + 增长率):把增长率转换成增长倍数。
cumprod():累计连乘。可以用增长率构造一个从 100 开始的收入指数。
fillna(0):第一年的增长率缺失,这里把它当作 0,让指数从 100 开始。
company_ts["收入指数"] = 100 * (1 + company_ts["收入增长率"].fillna(0)).cumprod() # 从 100 开始累计
company_ts[["证券简称", "年份", "营业收入_亿元", "收入增长率", "收入指数"]] # 查看收入指数
| 0 |
万科A |
2018 |
2976.79 |
NaN |
100.00 |
| 1 |
万科A |
2019 |
3678.94 |
0.24 |
123.59 |
| 2 |
万科A |
2020 |
4191.12 |
0.14 |
140.79 |
在每家公司内部计算时间变化
groupby("证券代码"):先按公司分组。
分组后使用 shift()、diff()、pct_change(),表示在每家公司内部计算上一年、增加额和增长率。
计算后要抽几家公司看一眼,确认不会把不同公司的年份接在一起。面板数据里直接对整列 shift() 很容易把上一家公司的最后一年错当成下一家公司的上一年。
panel_ts["上一年营业收入_亿元"] = panel_ts.groupby("证券代码")["营业收入_亿元"].shift(1) # 公司内部上一年收入
panel_ts[["证券代码", "证券简称", "年份", "营业收入_亿元", "上一年营业收入_亿元"]].head(12) # 查看上一年收入
| 0 |
000002 |
万科A |
2018 |
2976.79 |
NaN |
| 1 |
000002 |
万科A |
2019 |
3678.94 |
2976.79 |
| 2 |
000002 |
万科A |
2020 |
4191.12 |
3678.94 |
| 3 |
000004 |
国农科技 |
2018 |
3.67 |
NaN |
| 4 |
000004 |
国农科技 |
2019 |
1.08 |
3.67 |
| 5 |
000004 |
国华网安 |
2020 |
2.81 |
1.08 |
| 6 |
000006 |
深振业A |
2018 |
25.12 |
NaN |
| 7 |
000006 |
深振业A |
2019 |
37.31 |
25.12 |
| 8 |
000006 |
深振业A |
2020 |
29.35 |
37.31 |
| 9 |
000011 |
深物业A |
2018 |
27.87 |
NaN |
| 10 |
000011 |
深物业A |
2019 |
39.62 |
27.87 |
| 11 |
000011 |
深物业A |
2020 |
41.04 |
39.62 |
panel_ts["收入增加额_亿元"] = panel_ts.groupby("证券代码")["营业收入_亿元"].diff() # 公司内部收入增加额
panel_ts[["证券代码", "证券简称", "年份", "营业收入_亿元", "收入增加额_亿元"]].head(12) # 查看收入增加额
| 0 |
000002 |
万科A |
2018 |
2976.79 |
NaN |
| 1 |
000002 |
万科A |
2019 |
3678.94 |
702.15 |
| 2 |
000002 |
万科A |
2020 |
4191.12 |
512.18 |
| 3 |
000004 |
国农科技 |
2018 |
3.67 |
NaN |
| 4 |
000004 |
国农科技 |
2019 |
1.08 |
-2.59 |
| 5 |
000004 |
国华网安 |
2020 |
2.81 |
1.73 |
| 6 |
000006 |
深振业A |
2018 |
25.12 |
NaN |
| 7 |
000006 |
深振业A |
2019 |
37.31 |
12.19 |
| 8 |
000006 |
深振业A |
2020 |
29.35 |
-7.96 |
| 9 |
000011 |
深物业A |
2018 |
27.87 |
NaN |
| 10 |
000011 |
深物业A |
2019 |
39.62 |
11.75 |
| 11 |
000011 |
深物业A |
2020 |
41.04 |
1.42 |
panel_ts["收入增长率"] = panel_ts.groupby("证券代码")["营业收入_亿元"].pct_change() # 公司内部收入增长率
panel_ts[["证券代码", "证券简称", "年份", "营业收入_亿元", "上一年营业收入_亿元", "收入增长率"]].head(12) # 查看收入增长率
| 0 |
000002 |
万科A |
2018 |
2976.79 |
NaN |
NaN |
| 1 |
000002 |
万科A |
2019 |
3678.94 |
2976.79 |
0.24 |
| 2 |
000002 |
万科A |
2020 |
4191.12 |
3678.94 |
0.14 |
| 3 |
000004 |
国农科技 |
2018 |
3.67 |
NaN |
NaN |
| 4 |
000004 |
国农科技 |
2019 |
1.08 |
3.67 |
-0.71 |
| 5 |
000004 |
国华网安 |
2020 |
2.81 |
1.08 |
1.60 |
| 6 |
000006 |
深振业A |
2018 |
25.12 |
NaN |
NaN |
| 7 |
000006 |
深振业A |
2019 |
37.31 |
25.12 |
0.49 |
| 8 |
000006 |
深振业A |
2020 |
29.35 |
37.31 |
-0.21 |
| 9 |
000011 |
深物业A |
2018 |
27.87 |
NaN |
NaN |
| 10 |
000011 |
深物业A |
2019 |
39.62 |
27.87 |
0.42 |
| 11 |
000011 |
深物业A |
2020 |
41.04 |
39.62 |
0.04 |
# 筛选 2020 年收入增长率较高的公司。
high_growth_2020 = panel_ts.loc[
panel_ts["年份"] == 2020,
["证券代码", "证券简称", "行业名称", "营业收入_亿元", "上一年营业收入_亿元", "收入增长率"],
].sort_values("收入增长率", ascending=False)
high_growth_2020.head(10) # 查看 2020 年增长率靠前的公司
| 5 |
000004 |
国华网安 |
软件和信息技术服务业 |
2.81 |
1.08 |
1.60 |
| 53 |
000423 |
东阿阿胶 |
医药制造业 |
34.09 |
29.59 |
0.15 |
| 50 |
000403 |
派林生物 |
医药制造业 |
10.50 |
9.16 |
0.15 |
| 2 |
000002 |
万科A |
房地产业 |
4191.12 |
3678.94 |
0.14 |
| 56 |
000550 |
江铃汽车 |
汽车制造业 |
330.96 |
291.74 |
0.13 |
| 44 |
000338 |
潍柴动力 |
汽车制造业 |
1974.91 |
1743.61 |
0.13 |
| 23 |
000021 |
深科技 |
计算机、通信和其他电子设备制造业 |
149.67 |
132.24 |
0.13 |
| 26 |
000030 |
富奥股份 |
汽车制造业 |
111.13 |
100.64 |
0.10 |
| 47 |
000400 |
许继电气 |
电气机械及器材制造业 |
111.91 |
101.56 |
0.10 |
| 35 |
000070 |
特发信息 |
电气机械及器材制造业 |
47.22 |
43.28 |
0.09 |
日期索引和日期切片
set_index("日期列"):把日期列设为索引。
日期索引可以用字符串切片。例如年度数据可以用 loc["2020"] 取出 2020 年记录。
本章数据是年度数据,不适合重点演示 resample()。遇到日度交易数据或月度宏观数据时,再用 resample() 改变频率。
panel_by_date = panel_ts.set_index("统计截止日期").sort_index() # 日期索引
panel_by_date.loc["2020", ["证券代码", "证券简称", "行业名称", "营业收入_亿元", "收入增长率"]].head() # 取出 2020 年记录
| 统计截止日期 |
|
|
|
|
|
| 2020-12-31 |
000002 |
万科A |
房地产业 |
4191.12 |
0.14 |
| 2020-12-31 |
000559 |
万向钱潮 |
汽车制造业 |
108.82 |
0.03 |
| 2020-12-31 |
000011 |
深物业A |
房地产业 |
41.04 |
0.04 |
| 2020-12-31 |
000638 |
万方发展 |
软件和信息技术服务业 |
1.11 |
-0.04 |
| 2020-12-31 |
000555 |
神州信息 |
软件和信息技术服务业 |
106.86 |
0.05 |
阶段 8 小结:这一阶段从单家公司开始,依次看 shift()、diff()、pct_change() 的结果,再扩展到公司分组后的整张面板表。时间顺序计算完成后,先看单家公司,再看全部公司;这个顺序能减少面板数据中的错位问题。
练习:完成最后的阶段 8 练习。
练习
下面的练习继续使用本章两张表。练习只覆盖每一阶段的最低要求。每完成一步都看一眼结果,例如使用 head()、tail()、shape 或者简单统计。题目中的变量名是建议变量名,便于课堂核对。
阶段 1 练习:数据读取与初步查看
练习 1.1:查看经营表结构
读取 company_annual_operations_clean.xlsx,赋值给变量 annual_ex1。显示前 5 行和后 5 行,显示行列数、列名列表和各列数据类型。
练习 1.2:查看数值列的概况
继续使用 annual_ex1。显示 info() 和 describe() 的结果,观察这张表中有哪些列是数值列、哪些列是日期或文本列。
阶段 2 练习:行列选择与条件筛选
练习 2.1:找出低负债且盈利的公司
在 annual_ex1 中筛选同时满足以下条件的公司年度记录:净利润_亿元 > 0、资产负债率 < 0.6。结果赋值给变量 low_debt_profit,只保留 股票简称、统计截止日期、营业收入_亿元、净利润_亿元、资产负债率 五列。显示结果行数,并显示前 5 行。
练习 2.2:找出 2020 年资产规模较大的公司
在 annual_ex1 中筛选 2020 年、总资产_亿元 > 1000 的公司年度记录,赋值给变量 large_asset_2020。显示 股票简称、行业名称、总资产_亿元、资产负债率 四列,并查看前 5 行和后 5 行。
阶段 3 练习:变量生成与数据修改
练习 3.1:生成分析变量
把 annual_ex1 复制为 annual_ex3。在 annual_ex3 中生成 年份 和 净利率。年份 来自 统计截止日期 的年份部分;净利率 = 净利润_亿元 / 营业收入_亿元。显示 股票简称、统计截止日期、年份、营业收入_亿元、净利润_亿元、净利率 六列的前 8 行。
练习 3.2:按条件生成负债水平
在 annual_ex3 中新增 负债水平。规则是:资产负债率 >= 0.7 记为“较高”,其他记录记为“正常”。先全部赋值为“正常”,再用 .loc 把符合条件的行改为“较高”。显示 股票简称、年份、资产负债率、负债水平 四列的前 8 行。
练习 3.3:生成 2020 年收入排名
从 annual_ex3 中筛选 2020 年记录,赋值给变量 annual_2020_ex3。按 营业收入_亿元 从高到低排序,并生成 收入排名。收入排名 表示 2020 年公司营业收入从高到低的名次,收入最高为第 1 名。显示 股票简称、营业收入_亿元、净利润_亿元、收入排名 四列的前 10 行。
阶段 4 练习:常见数据问题处理
练习 4.1:清洗证券代码和日期
重新读取 financial_indicators_dirty.xlsx,赋值给变量 dirty_indicators_ex4。读取时把 证券代码 按字符串读取;把 --、缺失 和空字符串读成缺失;把 扣非净资产收益率、基本每股收益、非经常性损益_亿元、扣非净利润_亿元 指定为 float。读入后去掉 证券代码 和 股票简称 两端空格,把 证券代码 补齐为 6 位。把 统计截止日期 转成日期类型,并单独显示转换失败的记录。
练习 4.2:清理财务指标数值列
把 加权平均净资产收益率 按数值列转换;不能转换的异常写法保留为缺失。再确认 加权平均净资产收益率、扣非净资产收益率、基本每股收益、非经常性损益_亿元、扣非净利润_亿元 都是数值列。单独显示转换后的数据类型,再单独显示这几列的前 8 行。
练习 4.3:删除重复记录和关键缺失
按 证券代码 和 统计截止日期 删除重复记录。再用 dropna(subset=...) 删除连接键或五个指标列有缺失的记录,结果赋值给变量 indicators_clean_ex4。用 扣非净利润_亿元 > 0 生成 扣非盈利,表示扣除非经常性损益后的净利润是否为正。单独显示清理后的行数、每列缺失值数量和前 5 行。
阶段 5 练习:表的追加与合并
练习 5.1:纵向追加年度经营记录
重新读取 company_annual_operations_clean.xlsx,读取时把 证券代码 处理成 6 位字符串,并把 股票简称 重命名为 证券简称。把 2018-2019 年记录和 2020 年记录拆成两张表,再用 concat() 追加回一张表,赋值给变量 annual_panel_ex5。显示 证券代码、证券简称、统计截止日期、营业收入_亿元 的前 5 行和后 5 行。
练习 5.2:合并清洗后的指标表
把 annual_panel_ex5 和 indicators_clean_ex4 按 证券代码、统计截止日期 左连接,赋值给变量 analysis_ex5。显示 证券代码、证券简称、统计截止日期、营业收入_亿元、基本每股收益 的前 8 行。
练习 5.3:比较不同合并方式
构造两张小表 merge_left_ex5 和 merge_right_ex5。左表包含 3 家公司的 证券代码、证券简称、营业收入_亿元;右表包含其中 2 家公司的 证券代码 和 基本每股收益,并额外加入 1 家不在左表中的公司。分别用 how="left"、how="inner"、how="outer" 合并这两张小表,展示三个结果。
阶段 6 练习:分组汇总与组内比较
练习 6.1:行业年度摘要表
把 analysis_ex5 复制为 analysis_ex6,并生成 年份 和 净利率。年份 来自 统计截止日期 的年份部分;净利率 = 净利润_亿元 / 营业收入_亿元。按 行业名称 和 年份 分组,计算 公司数、营业收入合计_亿元、平均净利率、平均资产负债率,赋值给变量 industry_year_summary。其中 公司数 是每组不重复公司数量,营业收入合计_亿元 是每组营业收入求和,两个平均指标是每组对应列的均值。把分组结果整理成普通表,并显示前 12 行。
练习 6.2:判断公司是否高于行业平均
在 2020 年数据中,用 groupby() 和 transform() 计算每家公司所在行业的平均营业收入,生成 行业平均收入_亿元。再生成 高于行业平均。算法是:把公司自己的 营业收入_亿元 与 行业平均收入_亿元 比较,前者更大则为 True。显示 行业名称、证券简称、营业收入_亿元、行业平均收入_亿元、高于行业平均,并查看前 10 行。
阶段 7 练习:数据重塑与结果表构造
练习 7.1:构造公司收入宽表
用 pivot_table() 把 analysis_ex6 整理为宽表:以 证券代码、证券简称、行业名称 标识每家公司,年份为列,值为 营业收入_亿元。结果赋值给变量 revenue_wide_ex7。计算 收入增长率_2018_2020 = 2020 年营业收入 / 2018 年营业收入 - 1,显示前 10 行。
练习 7.2:整理公司结果表
把 revenue_wide_ex7 的索引还原成普通列,赋值给变量 company_summary_ex7。显示 证券代码、证券简称、行业名称、2018 年营业收入、2020 年营业收入、收入增长率_2018_2020 六列的前 10 行。再把 company_summary_ex7 的 证券代码 设为索引,并显示前 5 行。
阶段 8 练习:公司年度面板中的时间顺序
练习 8.1:计算单家公司收入变化
把 analysis_ex6 按 证券代码 和 统计截止日期 排序,赋值给变量 panel_ex8。选出任意一家公司,赋值给变量 one_company_ex8。计算 上一年营业收入_亿元、收入增加额_亿元、收入增长率。其中 上一年营业收入_亿元 是上一行的营业收入,收入增加额_亿元 = 本年营业收入 - 上一年营业收入,收入增长率 = 本年营业收入 / 上一年营业收入 - 1。显示该公司的全部年度记录。
练习 8.2:在公司内部计算收入增长率
在 panel_ex8 中按 证券代码 分组,计算每家公司内部的 上一年营业收入_亿元、收入增加额_亿元 和 收入增长率。三个变量的定义和练习 8.1 相同,但必须在每家公司内部计算。筛选 2020 年记录,按 收入增长率 从高到低排序,赋值给变量 top_growth_2020_ex8。显示 证券代码、证券简称、行业名称、营业收入_亿元、上一年营业收入_亿元、收入增加额_亿元、收入增长率 的前 10 行。